
ProxySQL支持查询缓存的功能 , 可以将后端返回的结果集缓存在自己的内存中 , 在某查询的缓存条目被清理(例如过期)之前 , 前端再发起同样的查询语句 , 将直接从缓存中取数据并返回给前端。如此一来 , ProxySQL处理的性能会大幅提升 , 也会大幅减轻后端MySQL Server的压力。
1. 开启query cache功能
ProxySQL的查询缓存功能由mysql_query_rules表中的cache_ttl字段控制 , 该字段设置每个规则对应的缓存时长 , 时间单位为毫秒。
当前端发送的SQL语句命中了某规则后(严格地说 , 是最后应用的那条规则 , 因为链式规则下会操作多个规则) , 如果这个规则同时还设置了"cache_ttl"字段的值 , 则这个SQL语句返回的结果将会被缓存一定时间 , 过期后将等待专门的线程(purge线程)来清理。
例如 :
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,apply,destination_hostgroup,match_pattern,cache_ttl)
values(1,1,1,10,"^select .* test1.t1",20000);
load mysql query rules to runtime;
save mysql query rules to disk;
select rule_id,destination_hostgroup,match_pattern,cache_ttl from mysql_query_rules;这表示匹配上述规则(查询test1.t1表)的查询结果集将在ProxySQL上缓存20秒。
可以执行下面的语句进行测试 , 每个语句循环执行10次 :
# 在bash下执行
proc="mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e"
for ((i=0;i<10;i++));do
$proc "select * from test1.t1;"
$proc "select * from test1.t2;"
$proc "select * from test2.t1;"
$proc "select * from test2.t2;"
done再去查看规则统计表 :
Admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 10 | <--rule_id=1的规则命中10次
+---------+------+
Admin> select hostgroup,count_star,sum_time,digest_text from stats_mysql_query_digest;
+-----------+------------+----------+------------------------+
| hostgroup | count_star | sum_time | digest_text |
+-----------+------------+----------+------------------------+
| -1 | 9 | 0 | select * from test1.t1 | <-- 9次 , hg="-1"
| 10 | 10 | 3640 | select * from test2.t1 |
| 10 | 10 | 3686 | select * from test2.t2 |
| 10 | 10 | 3986 | select * from test1.t2 |
| 10 | 1 | 1236 | select * from test1.t1 | <-- 1次,hg="10"
+-----------+------------+----------+------------------------+其中 , hostgroup=-1表示从缓存中取数据。
从上面的结果中 , 可以看出select * from test1.t1;语句除了被正常路由到后端执行的一次外 , 其它9次都是直接从缓存中获取数据的 , 且缓存取数据的语句执行总时间sum_time=0。
并不是所有的查询结果都应该缓存 , ProxySQL的缓存空间毕竟有限。所以很有必要去stats_mysql_query_digest表中找出哪些语句应该缓存 : 执行次数多、总执行时间长、平均执行时间长的语句都应该缓存。这些指标也是合理判断读、写分离的指标。
2.查询缓存相关的统计数据
ProxySQL虽然实现了查询缓存功能 , 但是查询缓存设计的还不够完整 , 缺少一些锦上添花的功能 , 例如能查询到的缓存类指标比较少 , 控制缓存的方式也比较缺乏。不过作者一直在努力改进 , 不断完善。
以下是和查询缓存有关的状态变量 :
Admin> SELECT * FROM stats_mysql_global WHERE Variable_Name LIKE '%Cache%';
+--------------------------+----------------+
| Variable_Name | Variable_Value |
+--------------------------+----------------+
| Stmt_Cached | 0 |
| Query_Cache_Memory_bytes | 0 |
| Query_Cache_count_GET | 0 |
| Query_Cache_count_GET_OK | 0 |
| Query_Cache_count_SET | 0 |
| Query_Cache_bytes_IN | 0 |
| Query_Cache_bytes_OUT | 0 |
| Query_Cache_Purged | 0 |
| Query_Cache_Entries | 0 |
+--------------------------+----------------+各变量的意义如下 :
Query_Cache_Memory_bytes: 查询结果集已成功缓存在内存中的总大小 , 不包含那些元数据;Query_Cache_count_GET: 从查询缓存中取数据的请求总次数(GET requests);Query_Cache_count_GET_OK: 成功从缓存中GET到缓存的请求总次数(即命中缓存且缓存未过期);Query_Cache_count_SET: 缓存到查询缓存中的结果集总数(即有多少个查询的结果集进行了缓存);Query_Cache_bytes_IN: 写入到查询缓存的总数据量;Query_Cache_bytes_OUT: 从查询缓存中取出的总数据量;Query_Cache_Purged: 从缓存中移除(purged)的缓存结果集(缓存记录)数量;Query_Cache_Entries: 当前查询缓存中还有多少个缓存记录。
无法查询当前缓存空间中的具体的缓存记录信息。
3. ProxySQL查询缓存的细节
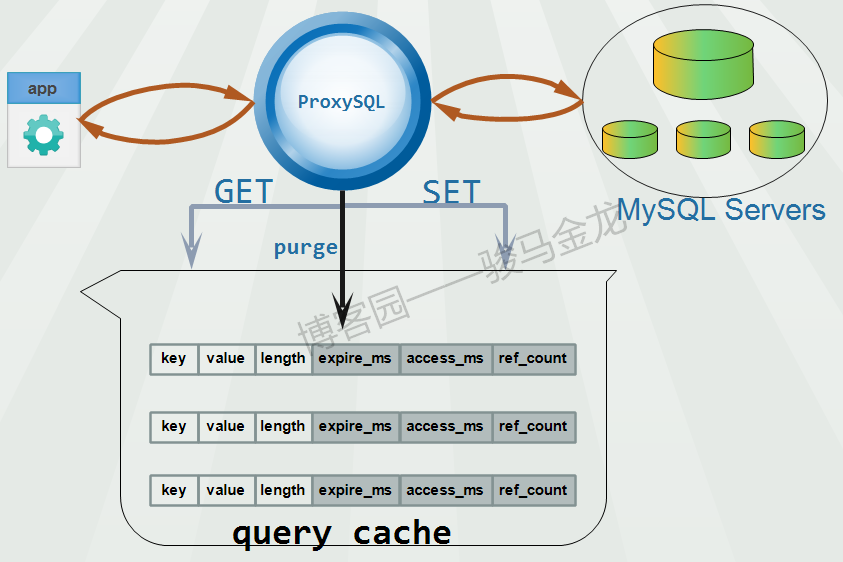
ProxySQL通过变量mysql_query_cache_size_MB控制为查询缓存开辟多大的空间 , 通过变量mysql-threshold_resultset_size定义ProxySQL能缓存的单个最大结果集大小。
Admin> show variables like '%size%';
+--------------------------------+-----------+
| Variable_name | Value |
+--------------------------------+-----------+
| mysql-eventslog_filesize | 104857600 |
| mysql-threshold_resultset_size | 4194304 | <<<<
| mysql-query_cache_size_MB | 256 | <<<<
| mysql-stacksize | 1048576 |
+--------------------------------+-----------+ProxySQL通过SET调用将后端返回的结果集放进查询缓存空间 , 通过GET调用从查询缓存空间取出缓存数据返回给前端。当GET调用发现缓存记录已过期 , 会将其放进purge队列中。
purge线程会定时清理purge队列中的过期记录 , 还会定时扫描缓存空间以找出过期记录。当查询缓存空间已经满了(mysql-query_cache_size_MB) , 下一次SET调用也会触发purge线程来清理已经过期的缓存记录。所以 , SET调用永远不会失败。但需要注意的是 , 如果已缓存内容占用的缓存空间低于3% , 则purge线程不会清理任何内容 , 即使它们已经过期了。
缓存记录的数据结构如下:
key:value:length:expire_ms:access_ms:ref_count其中:
key/value分别是缓存的id和实际缓存的数据 ,key是根据username + schemaname + SQL statement做hash运算得到的值 , 这可以保证用户只会访问到它自己的、指定schema的结果集。length用于记录缓存记录的长度。因为mysql-threshold_resultset_size变量的原因 , 超出该变量阈值的那部分额外结果集不会放进缓存。expire_ms:用来记录每个缓存记录还有多长时间过期。access_ms:记录每个缓存记录最近一次被访问离现在已多久。ref_count:记录各缓存记录当前被引用数量。每次GET调用某缓存记录 , 该缓存记录的ref_count都会加1, 调用完成后减1。这是为了避免正在调用的缓存记录正好过期又正好被purge线程发现而被清理。
所以 , 后面的3个字段都是为了让缓存记录过期而设计的。不过 , 目前ProxySQL还不支持根据access_ms来判断是否清理 , 例如缓存空间已满 , 且access_ms的时间已过去很久 , 但只要未过期 , 就不会被清理。这个字段可能是为以后的LRU(或其它类似缓存清理算法)做准备的。
4.容易误解的查询缓存
每个查询缓存记录的key是根据username + schemaname +SQL做hash运算出来的 , 这里的SQL是完整的包含参数SQL语句 , 而非参数化后的语句 , 如果SQL语句进行了重写 , 则使用重写后的完整的SQL语句参与hash运算。这很重要。
例如:
select * from tab where id between 10 and 20;
select * from tab where id between 10 and 19;
select * from tab where id=15;
select * from tab where id between 10 and 19;第一个语句会缓存id=10到id=20之间的结果集 , 但第二个语句和第三个语句不会从这个缓存记录中取数据 , 而是从后端查询后设置自己的缓存记录 , 即使第二个语句参数化后的语句和第一个完全一样(它们是同一类语句 , 如下代码所示) , 所需要的数据也已经被第一个语句缓存。第四个语句会命中第二个语句的缓存。
select * from tab where id between ? and ?但因为第二个语句和第一个语句命中的规则是同一个 , 所以这类语句的执行总次数会递增。
如下图:

参考链接
MySQL中间件之ProxySQL(9):ProxySQL的查询缓存功能 - 骏马金龙 - 博客园

