
1. 数据库基础概念
数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度(redundancy)、较高的数据独立性(data independency)和易扩展性(scalability),并可为各种用户共享。
概括地将,数据库数据具有永久存储、有组织和可共享三个基本特点。
数据库管理系统(DataBase Management System,DBMS)是位于用户与操作系统之间的一层数据管理软件。它的主要功能包括以下几个方面:
- 数据定义功能
- 数据库管理系统提供数据定义语言(
Data Definition Lanaguage,DDL),用户通过他可以方便地对数据库中的数据对象的组成与结构进行定义。
- 数据库管理系统提供数据定义语言(
- 数据组织、存储和管理
- 数据库管理系统要分类组织、存储和管理各种数据,包括数据字典、用户数据、数据的存取路径等。要确定以何中文件结构和存取方式在存储级上值这些数据,如何实现数据之间的联系。数据组织和存储的基本目标是提高存储空间利用率和方便存取,提供多种存取方式(如索引查找、hash查找、顺序查找等)来提高存取效率。
- 数据操纵功能
- 数据库管理系统还体用数据操纵语言(
Data Mainpulation Language,DML),用户可以使用它操纵数据,实现对数据库的基本操作,如查询、插入、删除和修改等。
- 数据库管理系统还体用数据操纵语言(
- 数据库的事务管理和运行管理
- 数据库在建立、运用和维护时由数据库管理系统统一管理和控制,以保证事务的正确运行,保证数据的安全性、完整性、多用户对数据的并发使用及发生故障后的系统恢复。
- 数据库的建立和维护功能
- 数据库的建立和维护功能包括数据库初始数据的输入、转换功能,数据库的转储、恢复功能,数据库的重组织功能和性能监视、分析功能等。这些功能通常是由一些实用程序或管理工具完成的。
- 其他功能
- 其他功能包括数据库管理系统与网络中其他软件系统的通信功能,一个数据库管理系统与另一个数据库管理系统或文件系统的数据转换功能,异构数据库之间的互访和互操作功能等。
数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员(DataBase Administrator,DBA)组成的存储、管理、处理和维护数据的系统。
2. 数据模型
数据模型(data model)是对现实世界数据特征的抽象。也就是说数据模型是用来描述数据、组织数据和对数据进行操作的。
数据模型是数据库系统的核心和基础。因此,了解数据模型的基本概念是学习数据库的基础。
数据模型应满足三方面要求:一是能比较真实地模拟现实世界,二是容易为人所理解,三是便于在计算机上实现。一个数据模型要很好地、全面地满足这三方面的要求在目前尚很困难。
根据模型应用的不同目的,可以将这些模型划分为两大类,它们分别属于两个不同的层次。第一类是概念模型,第二类是逻辑模型和物理模型。
- 第一类概念模型(
conceptual model),也称信息模型,它是按用户的观点来对数据和信息建模,主要用于数据库设计。 - 第二类中的逻辑模型主要包括层次模型(
hierarchical model)、网络模型(network model)、关系模型(relational model)、面向对象数据模型(object oriented data model)和对象关系数据模型(object relational data model),半结构化数据模型(semistructured data model)等。它是按计算机系统的观点对数据建模,主要用于数据库管理系统的实现。
2.1 概念模型
概念模型实际上时候现实世界到机器世界的一个中间层次。概念模型用于信息世界的建模,是现实世界到信息世界的第一层抽象。
信息世界主要涉及以下一些概念:
- 实体(
entity)- 客观存在并可相互区别的事物称为实体。实体可以是具体的人、事、物,也可以是抽象的概念或联系,例如,一个职工、一个学生、一个部门、一门课、学生的一次选课、部门的一次订货、教师与院系的工作关系(即某位教师在某院系工作)等都是实体
- 属性(
attribute)- 实体所具有的某些特性称为属性。一个实体可以有若干个属性来刻画。例如,学生实体可以由学号、姓名、性别、出生年月、所在院系、入学时间等属性组成,属性组合
(20131521,张山,男,199505,计算机系,2013)即表征了一个学生。
- 实体所具有的某些特性称为属性。一个实体可以有若干个属性来刻画。例如,学生实体可以由学号、姓名、性别、出生年月、所在院系、入学时间等属性组成,属性组合
- 码(
key)- 唯一标识实体的属性集称为码。例如学号是学生实体的码。
- 实体型(
entity type)- 具有相同属性的实体必然具有共同的特征和性质。用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。例如,
学生(学号,姓名,性别,出生年月,所在院系,入学时间)就是一个实体型。
- 具有相同属性的实体必然具有共同的特征和性质。用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。例如,
- 实体集(
entity set)- 同一类型实体的集合称为实体集。例如,全体学生就是一个实体集。
- 联系(
relationship)- 在现实世界中,事物内部以及事物之间是有联系的,这些联系在信息世界中反映为实体(型)内部的联系和实体(型)之间的联系。实体内部的联系通常是指组成实体的各属性之间的联系,实体之间的联系通常是指不同实体集之间的联系。
实体之间的联系有一对一、一对多和多对多等多种类型。
概念模型的一种表示方式: 实体-联系方法。
概念模型的表示方法很多,其中最为常用的是P.P.S.Chen 于1976年提出的实体-联系方法(Entity-Relationship approach)。该方法用E-R图(E-R diagram)来描述显示世界的概念模型,E-R方法也称为E-R模型。
2.2 数据模型的组成要素
一般地讲,数据模型是严格定义的一组概念的集合。这些概念精确地描述了系统的静态特性、动态特性和完整性约束条件(integrity constraints)。因此数据模型通常由数据结构、数据操作和数据的完整性约束条件三部分组成。
-
数据结构
数据结构描述数据库的组成对象以及对象之间的联系。也就是说,数据结构描述的内容有两类: 一类是与对象的类型、内容、性质有关的,如网状模型中的数据项、记录,关系模型中的域、属性、关系等:一类是与数据之间联系有关的对象,如网状模型中的系型(set type)。
数据结构是刻画一个数据模型性质最重要的方面。因此在数据库系统中,人们通常按照其数据结构的类型来命名数据模型。例如层次结构、网状结构和关系结构的数据模型分别命名为层次模型、网状模型和关系模型。
总之,数据结构是所描述的对象类型的集合,是对系统静态特性的描述。 -
数据结构
数据操作是指对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
数据库主要有查询和更新(包括插入、删除、修改)两大类操作。数据模型必须定义这些操作的确切含义、操作符号、操作规则(如优先级)以及实现操作的语言。
数据操作是对系统动态特性的描述。 -
数据的完整性约束条件
数据的完整性约束条件是一组完整性规则。完整性规则是给定的数据模型中数据及其联系所具有的制约和依存规则,用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效和相容。
数据模型应该反映和规定其必须遵守的基本的和通用的完整性约束条件。例如关系模型中,任何关系必须满足实体完整性和参照完整性两个条件。
数据模型还应该提供定义完整性约束条件的机制,以反映具体应用所涉及的数据必须遵纪守的特定的语意约束条件。例如,在某大学的数据库中规定学生成绩如果有6门以上不及格将不能授予学士学位,教授的退休年龄是65周岁,男职工的退休年龄是60周岁,女职工的退休年龄是55周岁等。
2.3 常用的数据模型
数据库领域中主要的逻辑数据模型有:
- 层次模型(
hierarchical model) - 网状模型(
network model) - 关系模型(
relatrional model) - 面向对象数据模型(
objetc oriented data model) - 对象关系数据模型(
object relational data model) - 半机构化数据模型(
semistructure data model)
其中层次模型和网状模型统称为格式化模型。
格式化模型的数据库在20世纪70年代至80年代初非常流行,在数据库系统产品中占据主导地址。层次数据库系统和网状数据库系统在使用和实现上都要涉及数据库物理层的复杂结构,现在已逐渐被关系模型的数据库系统取代。
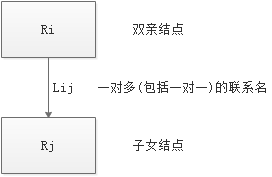
在格式化模型中数据结构的单位是基本层次联系。所谓基本层次联系是指两个记录以及它们之间的一对多(包括一对一)的联系。
图中Ri位于联系Lij的始点,称为双亲结点(parent),Rj位于联系Lij的终点,称为子女结点(child)
2.3.1 层次模型
层次模型数据结构
层次模型是数据库系统中最早出现的数据模型,层次数据库系统采用层次模型作为数据的组织方式。层次数据库系统的典型代表是IBM公司的IMS(Information Management System),这是1968年IBM公司推出的第一个大型商用数据库管理系统。
层次模型用树形结构来表示各类实体以及实体间的联系。现实世界中许多实体之间的联系本来就呈现出一种很自然的层次关系,如行政机构、家族关系等。
在数据库中定义满足下面两个条件的基本层次联系的集合为层次模型。
- 有且只有一个节点没有双亲节点,这个节点称为根节点 。
- 根以外的其他节点有且只有一个双亲节点。
在层次模型中,每个结点表示一个记录类型,记录类型之间的联系用结点之间的连线(有方向)表示,这个联系是父子之间的一对多的联系。这就使得层次数据库系统只能处理一对多的实体联系。
每个记录类型可包含若干个字段,这里记录类型描述的是实体,字段描述实体的属性。各个记录类型及其字段都必须命名。各个记录类型、同一记录类型中各个字段不能同名。每个记录类型可以定义一个排序字段,也称为码字段,如果定义该排序字段的值是唯一的,则它能唯一地标识一个记录值。
在层次模型中,同一双亲的子女结点称为兄弟结点(twin/sibling),没有子女接地那的节点称为叶结点。
层次模型的数据操纵与完整性约束
层次模型的数据操作主要有查询、插入、删除和更新。进行插入、删除、更新操作时要满足层次模型的完整性约束条件。
进行插入操作时,如果没有相应的双亲节点值就不能插入它的子女结点值。
进行删除操作时,如果删除双亲结点值,则相应的子女结点值也将被同时删除。
层次模型的优缺点
层次模型的优点主要有:
- 层次模型的数据结构比较简单清晰。
- 层次数据库的查询效率高。因为层次模型中记录之间的联系用有向边表示,这种联系在DBMS中常常用指针来实现。因此这种联系也就是记录之间的存取路径。当要存取某个节点的记录值,DBMS就沿着这一条路径很快找到该记录值,所以层次数据库的性能优于关系数据库,不低于网状数据库。
- 层次数据模型提供了良好的完整性支持。
层次模型的缺点主要有:
- 现实世界中很多联系是非层次性的。如结点之间具有多对多联系,不适合用层次模型表示。
- 如果一个结点具有多个双亲节点等,用层次模型表示这类联系就很笨拙,只能通过引入冗余数据(易产生不一致)或创建非自然的数据结构(引入虚拟节点)来解决。对插入和删除操作的限制比较多,因此应用程序的编写比较复杂。
- 查询子女结点必须通过双亲节点。
- 由于结构严密,层次命令趋于程序化。
可见,用层次模型对具有一对多的层次联系的部门描述非常自然、直观,容易理解。这是层次数据库的突出优点
2.3.2 网状模型
网络数据模型的典型代表是DBTG系统,亦称CODASYL系统。
网状模型的数据结构
在数据库中,把满足以下两个添加的基本层次联系集合称为网状模型:
- 允许一个以上的节点无双亲。
- 一个结点可以有多于一个的双亲
网络模型是一种比层次模型更具普遍性的结构。它去掉了层次模型的两个限制,允许多个结点没有双亲节点,允许节点有多个双亲节点;此外他还允许两个节点之间有多重联系(称之为复合联系)。因此,网状模型可以更直接地去描述现实世界。而层次模型实际上是网状模型的一个特例。
与层次模型一样,网状模型中每个节点表示一个记录类型(实体),每个记录类型可包含若干个字段(实体的属性),节点间的连线表示记录类型(实体)之间一对多的父子联系。
从定义可以看出,层次模型中子女结点与双亲节点的联系是唯一的,而在网状模型中这种联系可以不唯一。
网状模型的数据操纵与完整性约束
网状模型一般来说没有层次模型那样严格的完整性的约束条件,但具体的网状数据库系统对数据操纵都加了一些限制,提供了一定的完整性约束。
例如,DBTG 在模式数据定义语言中提供了定义DBTG数据库完整性的若干概念和语句,主要有:
- 支持记录码的概念,码即唯一标识记录的数据项的集合。例如,学生记录中学号是码,因此数据库中不允许学生记录中学号出现重复值。
- 保证一个联系中双亲记录和子女记录之间是一对多的联系。
- 可以支持双亲记录和子女记录之间的某些约束条件。例如,有些子女记录要求双亲记录存在才能插入,双亲记录删除时也连同删除。
网状模型的优缺点
- 网状模型的优点主要有:
- 能够更为直接的描述现实世界,如一个结点可以有多个双亲,结点之间可以有多种联系。
- 具有良好的性能,存取效率较高。
- 网状模型的缺点
- 结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握
- 网状模型的DDL、DML复杂,并且要嵌入某一种高级语言(如COBOL、C)中。用户不容易掌握,不容易使用。
- 由于记录之间的联系是通过存取路径实现的,应用程序在访问数据时必须选择适当的存取路径,因此用户必须了解系统结构的细节,加重了编写应用程序的负担。
2.3.3 关系模型
关系模型是最重要的一种数据模型。关系数据库系统采用关系模型作为数据的组织方式。
关系模型的数据结构
关系模型与以往的模型不同,它是建立在严格的数学概念的基础上的。从用户观点看,关系模型由一组关系组成。每个关系的数据结构是一张规范化的二维表。
| 学号 | 姓名 | 年龄 | 性别 | 系名 | 年级 |
|---|---|---|---|---|---|
| 2013004 | 王小明 | 19 | 女 | 社会学 | 2013 |
| 2013006 | 黄大鹏 | 20 | 男 | 商品学 | 2013 |
| 2013008 | 张文斌 | 18 | 女 | 法律 | 2013 |
| ... | ... | ... | ... | ... | ... |
- 关系(
relation) : 一个关系对应通常说的一张表。 - 元组(
tuple) : 表中的一行即为一个元组 - 属性(
attribute) : 表中的一列即为一个属性,给每一个属性起一个名称即属性名。上表有6列,对应6个属性(学号,姓名,年龄,性别,系名和年级)。 - 码(
key) :也称为码键。表中的某个属性组,它可以唯一确定一个元组,上表中的学号可以唯一确定一个学生,也就成为本关系的码。 - 域(
domain) : 域是一组具有相同数据类型的值的集合。属性的取值范围来自某个域。如人的年龄一般在1~120岁之间,大学生年龄属性的域是(15~45岁),性别的域是(男,女),系名的域是一个学校所有系名的集合。 - 分量 : 元组中的一个属性值。
关系模型要求关系必须是规范化的,即要求关系必须满足一定的规范条件,这些规范条件中最基本的一条就是,关系的每一个分量必须是一个不可分的数据项,也就是说,不允许表中还有表。
可以把关系和现实生活中的表格所使用的术语做一个粗略的对比,
| 关系术语 | 一般表格的术语 |
|---|---|
| 关系名 | 表名 |
| 关系模式 | 表头(表格的描述) |
| 关系 | (一张)二维表 |
| 元组 | 记录或行 |
| 属性 | 列 |
| 属性名 | 列名 |
| 属性值 | 列值 |
| 分量 | 一条记录中的一个列值 |
| 非规范关系 | 表中有表(大表中嵌有小表) |
关系模型的数据操纵和完整性约束
关系模型的数据操纵主要包括查询、插入、删除和更新数据。这些操作必须满足关系的完整性约束条件。关系的完整性约束条件包括三大类: 实体完整性、参照完整性和用户定义的完整性。
关系模型中数据操作是集合操作,操作对象和操作结果都是关系,即若干元组的集合,而不像格式化模型中那样是单记录的操作方式。另一方面,关系模型把存取路径向用户隐藏起来,用户只要指出"干什么"或"找什么",不必详细说明"怎么敢"或"怎么找",从而大大的提高了数据的独立性,提高了用户的生产率。
关系模型的优缺点
- 关系模型具有下列优点:
- 关系模型与格式化模型不同,它是建立在严格的数学概念的基础上的。
- 关系模型的概念单一。无论实体还是实体之间的联系都用关系来表示。对数据的检索和更新结果也是关系(即表)。所以其数据结构简单、清晰,用户易懂易用。
- 关系模型的存取路径对用户透明,从而具有更高的数据独立性、更好的安全保密性,也简化了程序园的工作和数据库开发建立的工作
当然,关系模型也有缺点,例如,由于存取路径对用户是隐藏的,查询效率往往不如格式化数据模型。为了提高性能,数据库管理系统必须对用户的查询请求进行优化,因此增加了开发数据库管理系统的难度。不过用户不必考虑这些系统内部的优化技术细节。
3. 关系数据库
关系数据库系统是支持关系模型的数据库系统。按照数据模型的三个要素,关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成。
3.1 关系数据结构
关系模型的数据结构非常简单,只包含单一的数据结构——关系。在用户看来,关系模型中数据的逻辑结构是一张扁平的二维表。
关系模型的数据结构虽然简单却能够表达丰富的语义,描述出现实世界的实体以及实体间的各种联系。也就是说,在关系模型中,现实世界的实体以及实体间的各种联系均用单一的结构类型,即关系来表示。关系模型是建立在集合代数的基础上的。
关系可以有三种类型: 基本关系(通常又称为基本表或基表)、查询表和视图表。其中,基本表示实际存在的表,它是实际存储数据的逻辑表示;查询表是查询结果对应的表;视图表是由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据。
关系模型要求关系必须是规范化(normalization)的,即要求关系必须满足一定的规范条件。这些规范条件中最基本的一条就是,关系的每一个分量必须是一个不可分的数据项。规范化的关系简称为范式(Normal Form,NF)
在关系数据模型中实体间的联系都用表来表示,但表是关系数据的逻辑模型。在关系数据库的物理组织中,有的关系数据库管理系统中一个表对应一个操作系统文件,将物理数据组织交给操作系统完成:有的关系数据库管理系统从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理。
3.2 关系操作
关系模型中常用的操作包括查询(query)操作和插入(insert)、删除(delete)、修改(update)操作两大部分。
关系的查询表达能力很强,是关系操作中最重要的部分。查询操作又可以分为选择(selete)、投影(project)、连接(join)、除(divide)、并(union)、差(except)、交(intersection)、笛卡儿积等。其中选择、投影、并、差、笛卡儿积是5种基本操作,其他操作可以用基本操作来定义和导出,就像乘法可以用加法来定义和导出一样。
还有一种介于关系代数和关系演算之间的结构化查询语言(Structured Query Language,SQL)。SQL不仅具有丰富的查询功能,而且具有数据定义和数据控制功能,是集查询、数据定义语言、数据操纵语言和数据控制语言(Data Control Language,DCL)于一体的关系数据语言。
特别地,SQL语言是一种高度非过程化的语言,用户不必请求数据库管理员为其建立特殊的存取路径,存取路径的选择由关系数据库管理系统的优化机制来完成。
3.3 关系的完整性
关系模型中有三类完整性约束: 实体完整性(entity integrity)、参照完整性(referentialintegrity)和用户定义的完整性(user-defined integrity)。其中实体完整性和参照完整性是关系模型必须满足的完整性约束条件,被称作是关系的两个不变性,应该由关系系统自动支持。用户定义的完整性是应用领域需要遵循的约束条件,体现了具体领域中的语义约束。
3.3.1 实体完整性
关系数据库中每个元组应该是可区分的,是唯一的。这样的约束条件用实体完整性来保证。
实体完整性规则 : 若属性(指一个或一组属性)A是基本关系R的主属性,则A不能取空值(null value)。所谓空值就是“不知道”或"不存在"或"无意义"的值。
对于实体完整性规则说明如下:
- 实体完整性规则是针对基本关系而言的。一个基本表通常对应现实世界的一个实体集。例如学生关系对应于学生集合。
- 现实世界中的实体是可区分的,即他们具有某种唯一性标识。例如每个学生都是独立的个体,是不一样的。
- 相应地,关系模型中以主码作为唯一性标识。
- 主码中的属性即主属性不能取空值。如主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,这与第(2)点相矛盾,因此这个规则称为实体完整性。
例如: 学生(学号,姓名,性别,专业号,年龄)关系中学号为主码,则学号不能取空值。
按照实体完整性规则的规定,如果主码由若干属性组成,则所有这些主属性都不能取空值。例如选修(学号,课程,成绩)关系中,"学号,课程号"为主码,则"学号"和"课程号"两个属性都不能取空值。
3.3.2 参照完整性
现实世界中的实体之间往往存在某种联系,在关系模型中实体及实体间的联系都是用关系来描述的,这样就自然存在着关系与关系间的引用。
设F是基本关系R的一个或一组属性,但不是关系R的码,Ks是基本关系S的主码。如果F与Ks相对应,则称F是R的外码(foreign key),并称基本关系R为参照关系(referencing relation),基本关系S为被参照关系(referenced relation)或目标关系(target relation)。关系R和S不一定是不同的关系。
显然,目标关系S的主码Ks和参照关系R的外码F必须定义在同一个(或同一组)域上

- 参照完整性规则 : 若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须:
- 如果取空值(F的每个属性值均为空值)
- 如果等于S中的某个元组的主码值
如下例中: 学生关系中每个元组的“专业号”属性只能取下面两类值:
空值 , 表示尚未给该学生分配专业
非空值 , 这时该值必须是专业关系中某个元组的"专业号"值,表示该学生不可能分配到一个不存在的专业中。即被参照关系"专业"中一定存在一个元组,它的主码值等于该参照关系"学生"中的外码值。
- 学生实体和专业实体可以用下面的关系来表示,其中主码用下划线标识。
- 学生( \underline{学号} , 姓名 , 性格 , 专业号 , 年龄 )
- 专业 ( \underline{专业号}, 专业名 )
- 这两个关系之间存在着属性的引用,即学生关系引用了专业关系的主码"专业号"。显然,学生关系中的"专业号"值必须是确实存在的专业的专业号,即专业关系中有该专业的记录。也就是说,学生关系中的某个属性的取值需要参照专业关系的属性取值。
- 学生、课程、学生与课程之间的多对多联系可以如下三个关系表示
- 学生 ( \underline{学号}, 姓名 , 性别 , 专业号 , 年龄)
- 课程 ( \underline{课程号 } , 课程名 , 学分)
- 选修 ( \underline{学号,课程号}, 成绩)
- 这三个关系之间也存在着属性的引用,即选修关系引用了学生关系的主码"学号"和课程关系的主码"课程号"。同样,选修关系中的"学号"值必须是确实存在的学生的学号,即学生关系中有该学生的记录: 选修关系中的" 课程号"值也必须是确实存在的课程的课程号,即课程关系中有该课程的记录。换句话说,选修关系中某些属性的取值需要参照其他关系的属性取值。
- 在学生( \underline{学号},姓名, 性别,专业号 ,年龄, 班长) 关系中,"学号"属性是主码,"班长"属性表示该学生所在班级的班长的学号,它引用了本关系"学号"属性,即"班长"必须是确实存在的学生的学号。
3.3.3 用户定义的完整性
用户定义的完整性就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。例如某个属性必须取唯一值、某个非主属性不能取空值等。例如学生关系中,若按照应用的要求学生不能没有姓名,则可以定义学生姓名不能取空值:某个属性(如学生的成绩)的取值范围可以定义0~100之间等。
3.4 关系代数
关系代数是一种抽象的查询语言,它用对关系的运算来表达查询。
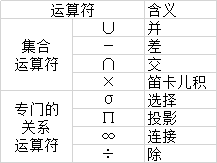
关系代数的运算对象是关系,运算结果亦为关系。关系代数用到的运算符包括两类: 集合运算符合和专门的关系运算符。
3.4.1 传统的集合运算
传统的集合运算是二目运算,包括并、差、交、笛卡儿积 4种运算。
设关系R和关系S具有相同的目n(即两个关系都有n个属性),且相应的属性取自同一个域,t是元组变量,$t \in R $ 表示t是R的一个元组
-
并(
union)
关系R与关系S的并记作 : R\cup S= \lbrace{t | t \in R \vee t \in S \rbrace}
其结果仍为n目关系,由属于R或S的元组组成。 -
差(
except)
关系R与关系S的差记作 : R-S=\lbrace{ t | t \in R \wedge t \notin S \rbrace}
其结果关系仍为n目关系,由属于R而不属于S的所有元组组成 -
交(
intersection)
关系R与关系S的交记作 : R \cap S= \lbrace{ t | t \in R \wedge t \in S\rbrace}
其结果关系仍为n目关系,由既属于R又属于S的元组组成。关系的交可以用差来表示,即R \cap S = R- (R-S) 。 -
笛卡儿积(
cartesian product)
这里的笛卡尔积严格的讲应该是广义的笛卡尔积,因为这里笛卡尔积的元素是元组。
两个分别为n目和m目的关系R和S的笛卡儿积是一个(n+m)列的元组的集合。元组的前n列是关系R的一个元组,后m列是关系S的一个元组。若R有k_1个元组,S有k_2个元组,则关系R和关系S的笛卡尔积有k_1×k_2个元组。记作 : R \times S \lbrace{ \widehat{t_rt_s } | t_r \in R \wedge t_s \in S \rbrace}

3.4.2 专门关系运算
专门的关系运算包括选择、投影、连接、除运算等。
Student表格如下
| Sno | Sname | Ssex | Sage | Sdept |
|---|---|---|---|---|
| 201215122 | 刘晨 | 女 | 19 | CS |
| 201215123 | 王敏 | 女 | 18 | MA |
| 201215125 | 张立 | 男 | 19 | IS |
-
选择(
selection)
选择又称为限制(restriction),它是在关系R中选择满足给定条件的诸元组,记作:\large\sigma_F(R)= \lbrace{ t | t \in \small R \wedge F_{(t)} = 真 \rbrace}
其中F表示选择条件,它是一个逻辑表达式,取逻辑值“真” 或 “假”。示例
查询表格student表格中信息系(IS系)全体学生 : \large \sigma_{\small Sdept='IS'} \small (Student )Sno Sname Ssex Sage Sdept 201215125 张立 男 19 IS -
投影(
projection)
关系R上的投影是从R中选择出若干属性列组成新的关系。记作\prod_A(R)= \lbrace{ t[A] | t \in R \rbrace}
投影操作是从列的角度进行运算。示例
查询学生的姓名和所在系,即求Student关系上学生姓名和所在系两个属性上的投影 : \prod_{Sname.Sdept}(Student) 。
Sname Sdept 李勇 CS 刘晨 CS 王敏 MA 张立 IS -
连接(
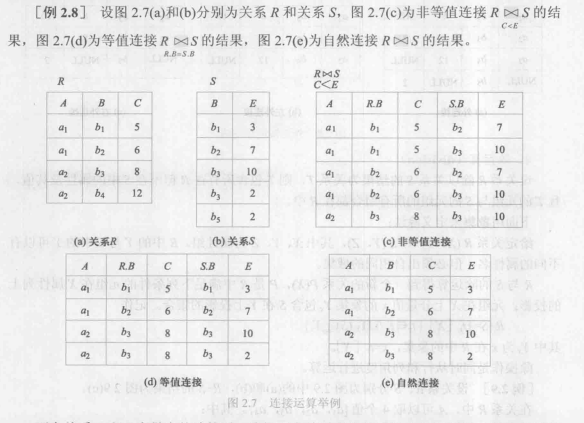
join)连接也称为\theta 连接。它是从两个关系的笛卡儿积中选取属性间满足一定条件的元组。记作:
R \mathop{\bowtie}\limits_{A \theta B} S = \lbrace{ \widehat{t_rt_s} | t_r \in R \wedge t_s \in S \wedge t_r[A] \theta t_s[B] \rbrace}其中,A和B分别为R和S上列数相等且可比的属性组,\theta是比较运算符。连接运算从R和S的笛卡儿积\rm R \times S 中选取R关系在A属性组上的值与S关系与B属性组上的值满足比较关系\theta的元组。
连接运算中有两种最为重要也最为常用的连接,一种是等值连接(
equijoin),另一种是自然连接(natural join)。\theta 为“=”的连接运算称为等值连接。它是从关系R与S的广义笛卡儿积中选取A、B属性值相等的那些元组,即等值连接为
\rm R \mathop{\bowtie}\limits_{A=B}S= \lbrace{\widehat{t_rt_s }| t_r \in R \wedge t_s \in S \wedge t_r[A]=t_s[B] \rbrace}自然连接是一种特殊的等值连接。它要求两个关系中进行比较的分量必须是同名的属性组,并且在结果中把重复的属性列去掉。即若R和S中具有相同的属性组B,\cup为R和S的全体属性集合,则自然连接可记作
\rm R \bowtie S = \lbrace{ \widehat{t_rt_s}[U-B] | t_r \in R \wedge t_s \in S \wedge t_r[B]=t_s[B] \rbrace}一般的连接操作是从行的角度进行运算,但自然连接还需要取消重复列,所以是同时从行和列的角度进行运算
-
除运算(
division)
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与S的元组的所有组合都在R中。
给定关系R(X,Y)和S(Y,Z),其中X,Y,Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集。
R与S的除运算得到的一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上分量值x的象集\rm Y_x包含S在Y上投影的集合。记作\rm R \div S = \lbrace{ t_r [X] | t_r \in R \wedge \Pi_y(S) \subseteq Y_x \rbrace}其中\rm Y_x为x在R中的象集, \rm x = t_r [X]

3.5 范式
关系数据库中的关系是要满足一定要求的,满足不同程度要求的为不同范式。满足最低要求的叫第一范式,简称1NF;在第一范式中满足进一步要求的为第二范式,其余以此类推。
一个低一级范式的关系模式通过模式分解(schema decomposition)可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化(normalization)。
一个关系模式应当是一个五元组: R(U,D,DOM,F)
- 关系名R是符号化的元组语义
- U为一组属性。
- D为属性组U中的属性所有来自的域。
- DOM为属性到域的映射
- F为属性组U上的一组数据依赖。
由于D、DOM与模式设计关系不大,因此在该节中把关系模式看作一个三元组:R(U,F)
函数依赖 : 设一个关系为R(U),X和Y为属性集U上的子集,若对于X上的每个值都有Y上的一个唯一值与之对应,则称X和Y具有函数依赖关系,并称X函数决定Y,或称Y 函数依赖于X,记作\rm{X} \rightarrow \rm{Y},称X为决定因素。
函数依赖可以简单理解X和Y分别对应二维表中的两列, X 列中的每个值都有一个对应的B列中唯一一个值,X中不能有重复行。此时称为函数依赖
部分函数依赖 : 设一个关系为R(U),X和Y为属性集U上的子集,若存在\rm{X} \rightarrow \rm{X},同时X的真子集X'也能够函数决定Y,即存在\rm{X'} \rightarrow Y,则称\rm{X \rightarrow Y}的函数依赖为部分函数依赖,或者说X 部分函数决定Y,Y部分函数依赖于X。记作 : \rm {X \mathop{\rightarrow}\limits^P Y}。
完全函数依赖 : 在R(U)中,如果\rm{X} \rightarrow \rm{Y},并且对于X的任何一个真子集X',都有\rm{X' \nrightarrow Y},则称Y对X完全函数依赖,记作 : \rm {X \mathop{\rightarrow}\limits^F Y}
传递函数依赖 : 在R(U)中,如果\rm {X \rightarrow Y (Y \nsubseteq Z)} ,\rm {Y \nrightarrow X , Y \rightarrow Z ,Z \nsubseteq Y } 则称Z对X传递函数依赖。记为 \rm {X \mathop{\rightarrow}\limits^{传递} Z}
码是关系模式中的一个重要概念。设K为R<U,F>中的属性或属性组合,若\rm {K \mathop{\rightarrow}\limits^F U },则K为R的候选码。
若候选码多于一个,则选定其中的一个为主码。包含在任何一个候选码中的属性称为主属性;不包含在任何候选码中的属性称为非主属性或非码属性。
3.5.1 第一范式
作为一个二维表,关系要符号一个最基础的条件:每一个分量必须是不可分的数据项,每一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复属性。除去同类型的字段,就是无重复的列。满足了这个条件的关系模式就属于第一范式(1NF)。
| 编号 | 品名 | 进货 | 销售 | 备注 | ||
| 数量 | 单价 | 数量 | 单价 | |||
上面表格中可以看到在进货以及销售中,分别都包含了数量以及单价两列。因此这样不符合第一范式。如果需要优化为第一范式的表格,可以优化为如下表格。
| 编号 | 品名 | 进货单价 | 进货数量 | 销售数量 | 销售单价 | 备注 |
|---|
3.5.2 第二范式
定义
如果仅仅是将表格优化为第一范式。仍然会有很多问题。
| 学号 | 姓名 | 系名 | 系主任 | 课名 | 分数 |
|---|---|---|---|---|---|
| 1022211101 | 李小明 | 经济系 | 王强 | 高等数学 | 95 |
| 1022211101 | 李小明 | 经济系 | 王强 | 大学英语 | 87 |
| 1022211101 | 李小明 | 经济系 | 王强 | 普通化学 | 76 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 高等数学 | 72 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 大学英语 | 98 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 计算机基础 | 88 |
| 1022511101 | 高芳芳 | 法律系 | 刘玲 | 高等数学 | 82 |
| 1022511101 | 高芳芳 | 法律系 | 刘玲 | 法学基础 | 82 |
- 数据冗余过大 : 每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应系主任的数据也重复多次。
- 插入异常 : 假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的。
- 更新异常 : 由于数据冗余,当更新数据库中的数据时,系统要付出很大的代价来维护数据库的完整性。如果李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。
- 删除异常 : 如果某个系的学生全部毕业了,则在删除该系学生信息的同时,这个系及其系主任的信息也丢掉了。
一个好的模式应当不会发生插入异常、删除异常和更新异常,数据冗余应尽可能少。
有学号(Sno)、姓名(Sname)、系名(Sdept)等几个属性。由于一个学号只对应一个学生,一个学生只在一个系学习。因而当"学号"值确定之后,学生的姓名及所在系的值也就被唯一地确定了。属性间的这种依赖关系类似于数学中的函数y=f(x),自变量x确定之后,相应的函数值y也就唯一地确定了。
类似的有Sname=f(Sno),Sdept=f(Sno),即Sno函数决定Sname,Sno函数决定Sdept,或者说Sname和Sdept函数依赖于Sno,记作\rm {Sno \rightarrow Sname},\rm {Sno \rightarrow Sdept}。
若\rm {R \in 1NF} ,且每一个非主属性完全依赖于任何一个候选码,则\rm {R \in 2NF}。因此可以判断上面的表格不属于第二范式。
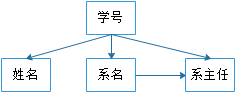
上表中依赖关系图如下:
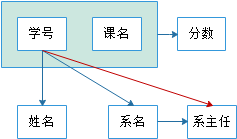
表格中的码只有一个,就是 (学号,课名)。
主属性有两个: 学号与课名。
非主属性有四个 : 姓名、系名、系主任、分数
对于 (学号,课名)-->姓名 ,有 (学号-->姓名) ,存在非主属性 姓名 对码(学号,课名) 的部分函数依赖。
对于 (学号,课名)-->系名 ,有 学号-->系名 ,存在非主属性 系名 对码(学号,课名) 的部分函数依赖。
对于 (学号,课名)-->系主任 ,有 学号--> 系主任 ,存在非主属性 对码(学号,课名) 的部分函数依赖。
非主属性对于码的部分函数依赖,最高只符合1NF的要求,不符合2NF的要求。
为了让表符合2NF的要求,我们必须消除这些部分函数依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表,在拆分的过程中,要达到更高一级范式的要求,这个过程叫做模式分解。模式分解的方法不是唯一的,以下是其中一种方法:
- 选课(学号,课名,分数)
- 学生(学号,姓名,系名,系主任)
此时依赖关系如下:

对于选课表,其码是(学号,课名),主属性是学号和课名,非主属性是分数,学号确定,并不能唯一确定分数,课名确定,也不能唯一确定分数,所以不存在非主属性分数对于码(学号,课名)的部分函数依赖,所以词表符合2NF的要求。
对于学生表,其码是学号,主属性是学号,非主属性是姓名、系名和系主任,因为码只有一个属性,所以不可能存在非主属性对于码的部分函数依赖,所以此表符合2NF的要求。
3.5.3 第三范式
设关系模式\rm{R<U,F>\in 1NF},若R中不存在这样的码X,属性Y及非主属性\rm {Z(Z \nsupseteq Y )}使得\rm{X \rightarrow Y , Y \rightarrow Z} 成立, \rm{Y \nrightarrow X},则称\rm {R<U,F> \in 3NF}。
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。也就是说,如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。
对于选课表,主码为(学号,课名),主属性为学号和课名,非主属性只有一个,为分数,不可能存在存在传递函数依赖,所以选课表的设计,符号3NF的要求。
对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为学号-->系名,同时系名--->系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。
为了让数据表设计达到3NF,我们必须进一步进行模式分解为以下形式:
- 选课(学号,课名,分数)
- 学生(学号,姓名,系名)
- 系(系名,系主任)
对于选课表,符合3NF的要求,之前已经分析过了。
对于学生表,码为学号,主属性为学号,非主属性为系名,不可能存在非主属性对于码的传递函数依赖,所以符合3NF的要求。
对于系表,码为系名,主属性为系名,非主属性为系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),所以符合3NF的要求。
结论:
由此可见,符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到2NF或者1NF,但是作为数据库设计人员,至少应该知道,3NF的要求是怎样的。
3.5.4 巴德斯科范式
BCNF(Boyee Codd Normal Form)通常认为BCNF是修正的第三范式,有时也称为扩充的第三范式。关系模式\rm {R<U,F> \in 1NF,若X \rightarrow Y 且Y \nsubseteq X 时X必含有码,则 R<U,F> \in BCNF}`。
由BCNF的定义得到结论,一个满足BCNF的关系模式有:
- 所以非主属性对每一个码都是完全函数依赖。
- 所有主属性对每一个不包含它的码也是完全函数依赖
- 没有任何属性完全函数依赖于非码也是完全函数依赖。
某公司有若干个仓库 ; 每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作 ;
一个仓库中可以存放多种物品 , 一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。
那么关系模式 仓库(仓库名,管理员,物品名,数量)中 ,
已知函数依赖集 : 仓库名→管理员,管理员→仓库名, (仓库名 , 物品名)→数量 。
码 : (管理员 , 物品名) ,( 仓库名 ,物品名)。
主属性 : 仓库名、管理员、物品名
非主属性 : 数量
因为不存在非主属性对码的部分函数依赖和传递函数依赖 ,所以这个关系为3NF。
| 仓库名 | 管理员 | 物品名 | 数量 |
|---|---|---|---|
| 上海仓 | 张三 | iPhone 5s | 30 |
| 上海仓 | 张三 | iPad Air | 40 |
| 北京仓 | 李四 | iPhone 5s | 50 |
| 北京仓 | 李四 | iPad Mini | 60 |
-
先新增加一个仓库 , 但尚未存放任何物品 , 是否可以为该仓库指派管理员?
不可以 , 因为物品名也是主属性 , 根据实体完整性的要求 , 主属性不能为空。
-
某仓库被清空后 , 需要删除所有与这个仓库相关的物品存放记录 , 会带来什么问题?
仓库本身与管理员的信息也被随之删除了。
-
如果某仓库更换了管理员 , 会带来什么问题?
这个仓库有几条物品存放记录,就要修改多少次管理员信息。
从这里我们可以得出结论 , 在某些特殊情况下 , 即使关系模式符合 3NF 的要求 , 仍然存在着插入异常 ,修改异常与删除异常的问题 ,仍然不是 ”好“ 的设计。
造成此问题的原因:存在着主属性对于码的部分函数依赖与传递函数依赖。(在此例中就是存在主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。)
解决办法就是要在 3NF 的基础上消除主属性对于码的部分与传递函数依赖。
仓库(仓库名 , 管理员)
库存(仓库名 ,物品名 ,数量)
这样 , 之前的插入异常 , 修改异常与删除异常的问题就被解决了。
4. 数据库恢复技术
4.1 事务
事务 是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。例如,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。
事务和程序是两个概念。一般地将,一个程序中包含多个事务。
事务的开始与结束可以由用户显示控制。如果用户没有显式的定义事务,则由数据库管理系统按默认规定自动划分事务。在SQL中,定义事务的语句一般有三条:
BEGIN TRANSACTION;
COMMIT;
ROLLBACK;
事务通常是以BEGIN TRANSACTION开始,以COMMIT或ROLLBACK结束。COMMIT表示提交,即提交事务的所有操作。具体地说就是将事务中所有对数据库的更新写回到磁盘上的物理数据库中去,事务正常结束。ROLLBACK表示回滚,即在事务运行的过程中发生了某些故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态。
事务具有4个特性 : 原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持续性(Durability)。这4个特性简称为ACID特性(ACID properties)
-
原子性
事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做。 -
一致性
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。如果数据库系统运行中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。 -
隔离性
一个事务的执行不能被其他事务干扰。即一个事务的内部操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能相互干扰。 -
持续性
持续性也称永久性(Permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
参考链接 :


