
DMLinsert) ,更新(update) ,删除(delete)和查询(select) , 是开发人员日常使用最频繁的操作。
1. INSERT语句
1.1 基础功能介绍
功能 : 一次插入一行或多行数据
语法
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] {VALUES | VALUE} ({expr | DEFAULT},...),(...),... [ ON DUPLICATE KEY UPDATE #如果重复更新之 col_name=expr [, col_name=expr] ... ] INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name SET col_name={expr | DEFAULT}, ... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ] INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] SELECT ... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ]选项说明
LOW_PRIORITY:如果使用LOW_PRIORITY关键词 , 则INSERT的执行被延迟 , 直到没有其它客户端从表中读取为止。当原有客户端正在读取时 , 有些客户端刚开始读取。这些客户端也被包括在内。此时 ,INSERT LOW_PRIORITY语句等候。因此 ,在读取量很大的情况下,发出INSERT LOW_PRIORITY语句的客户端有可能需要等待很长一段时间(甚至是永远等待下去)。DELAYED: 是立刻返回一个标识 , 告诉上层程序 , 数据已经插入了 , 当表没有被其它线程使用时 , 此行被插入 , 真实插入时间就不可控了。所以这样的写法对数据的安全性是没有保障的。HIGH_PRIORITY: 如果你指定了HIGH_PRIORITY修饰符 , 它会覆盖掉服务器启动时的--low-priority-updates选项。修饰符影响那些只支持表级锁的存储引擎 , 比如 :MyISAM,MEMORY, 和MERGE。之所以INSERT可以设置HIGH_PRIORITY, 是因为要通过它来阻止并发插入行为。IGNORE:insertignore表示 , 如果中已经存在相同的记录 , 则忽略当前新数据 , 主键和唯一键为基准;MySQL服务器会在执行INSERT操作期间忽略那些可忽略的错误。这些错误最终会作为WARNING返回。
LOW_PRIORITY关键字应用于DELETE、INSERT、LOAD DATA、REPLACE和UPDATE。HIGH_PRIORITY关键字应用于SELECT和INSERT语句。DELAYED关键字应用于INSERT和REPLACE语句。
有上面语法可以知道,INSERT共有三种语法使用方式。
插入单行
INSERT INTO table_name (column_1, column_2, ...) VALUES (value_1, value_2, ...);同时也可以使用
INSERT ... SET命令(此方法无法插入空值)INSERT INTO table_name SET column_1 = value_1 ,colume_2 = value_2 , ...;插入多行
INSERT INTO table_name (column_1, column_2, ...) VALUES (value_11, value_12, ...), (value_21, value_22, ...) ...;从其他表中获取数据插入到指定表中
#两个表的表结构一样 INSERT INTO table_name SELECT语法 #两个的表的表结构不一样, INSERT INTO table_name (colume_1, column_2,...) SELECT语法
1.2 INSERT限制
在 MySQL 中 , max_allowed_packet 配置了服务器和客户端任何单个消息大小的上限。这同样适用于 SELECT 语句。当一个 SELECT 语句的大小超过 max_allowed_packet 值时 , 服务器就会给出一个错误。
以下语句显示了当前服务器上的 max_allowed_packet 配置 :
SHOW VARIABLES LIKE 'max_allowed_packet';+--------------------+----------+
| Variable_name | Value |
+--------------------+----------+
| max_allowed_packet | 67108864 |
+--------------------+----------+
1 row in set (0.00 sec)max_allowed_packet 以字节为单位。并且不同服务器上的值可能不同。
1.3 MySQL INSERT 与ON DUPLICATE KEY UPDATE
INSERT ... ON DUPLICATE KEY UPDATE是MySQL insert的一种扩展。当发现有重复的唯一索引(unique key)或者主键(primary key)的时候 , 会进行更新操作 ; 如果没有 , 那么执行插入操作。
这样使用的好处是能够节省一次查询判断。如果有个业务的场景是 , 有过有这条数据 , 那么进行更新 , 如果没有 , 那么进行新增插入操作。
如果不使用INSERT ... ON DUPLICATE KEY UPDATE, 那么一种比较常见的解决思路是 , 先按照unque key查询 , 是否存在这条数据 , 如果不存在 , 直接新增。如果存在这条数据 , 那么比对其余值是否一致 , 如果不一致 , 那么则进行更新操作 , 否则什么都不需要操作。
如果新行违反主键(PRIMARY KEY)或UNIQUE约束, MySQL会发生错误。例如 , 如果执行以下语句:
INSERT INTO tasks(task_id,subject,start_date,end_date,description)
VALUES (4,'Test ON DUPLICATE KEY UPDATE','2017-01-01','2017-01-02','Next Priority');MySQL很不高兴 , 并向你扔来一个错误消息 :
Error Code: 1062. Duplicate entry '4' for key 'PRIMARY' 0.016 sec因为表中的主键task_id列已经有一个值为 4 的行了 , 所以该语句违反了PRIMARY KEY约束。
但是 , 如果在INSERT语句中指定ON DUPLICATE KEY UPDATE选项 , MySQL将插入新行或使用新值更新原行记录。
例如 , 以下语句使用新的task_id和subject来更新task_id为4的行。
INSERT INTO tasks(task_id,subject,start_date,end_date,description)
VALUES (4,'Test ON DUPLICATE KEY UPDATE','2017-01-01','2017-01-02','Next Priority')
ON DUPLICATE KEY UPDATE
task_id = task_id + 1,
subject = 'Test ON DUPLICATE KEY UPDATE';执行上面语句后 , MySQL发出消息说2行受影响。现在 , 我们来看看tasks表中的数据 :
mysql> select * from tasks;
+---------+------------------------------+------------+------------+------------------+
| task_id | subject | start_date | end_date | description |
+---------+------------------------------+------------+------------+------------------+
| 1 | Learn MySQL INSERT | 2017-07-21 | 2017-07-22 | Start learning.. |
| 2 | 任务-1 | 2017-01-01 | 2017-01-02 | Description 1 |
| 3 | 任务-2 | 2017-01-01 | 2017-01-02 | Description 2 |
| 5 | Test ON DUPLICATE KEY UPDATE | 2017-01-01 | 2017-01-02 | Description 3 |
+---------+------------------------------+------------+------------+------------------+
4 rows in set新行没有被插入 , 但是更新了task_id值为4的行。上面的INSERT ON DUPLICATE KEY UPDATE语句等效于以下UPDATE语句 :
UPDATE tasks
SET
task_id = task_id + 1,
subject = 'Test ON DUPLICATE KEY UPDATE'
WHERE
task_id = 4;2. REPLACE 语句
在MySQL中 , 如果你想向表中插入数据 , 除了使用 INSERT 语句 , 还可以使用 REPLACE 语句。
REPLACE 语句和 INSERT 语句很像 , 它们的不同之处在于 , 当插入过程中出现了重复的主键或者重复的唯一索引的时候 , INSERT 语句会产生一个错误 , 而 REPLACE 语句则先删除旧的行 , 再插入新的行。
REPLACE 语句不在标准 SQL 的范畴。
语法
REPLACE [LOW_PRIORITY | DELAYED] [INTO] tbl_name [(col_name,...)] {VALUES | VALUE} ({expr | DEFAULT},...),(...),... Or: REPLACE [LOW_PRIORITY | DELAYED] [INTO] tbl_name SET col_name={expr | DEFAULT}, ... Or: REPLACE [LOW_PRIORITY | DELAYED] [INTO] tbl_name [(col_name,...)] SELECT ...我们可以使用一个
REPLACE语句插入一行或多行数据。REPLACE语句的语法如下 :REPLACE [INTO] table_name (column_1, column_2, ...) VALUES (value_11, value_12, ...), (value_21, value_22, ...) ...;说明 :
REPLACE INTO和VALUES都是关键字。INTO可省略。REPLACE INTO后跟表名table_name。表名
table_name后跟要插入数据的列名列表。列名放在小括号中 , 多个列表使用逗号分隔。VALUES关键字之后的小括号中是值列表。值的数量要和字段的数量相同。值的位置和列的位置一一对应。当插入多行数据时 , 多个值列表之间使用逗号分隔。
REPLACE 语句与 INSERT 语句类似。
REPLACE 语句还可以使用 SET 关键词 , 这只适用于操作单行。语法如下 :
REPLACE [INTO] table_name
SET column1 = value1,
column2 = value2,
...;这种用法与 UPDATE语句的相似 , 但也是不同的。 UPDATE 只更新符合条件的行的指定字段的值 , 未指定的字段保留原值。REPLACE 则会删掉旧行 , 再插入新行 , REPLACE 语句中未指定的字段则为默认值或者 NULL。
如果想要正常使用 REPLACE , 当前操作的用户必须对表具有 INSERT 和 DELETE权限。
3. UPDATE 语句
语法:
单表更新语法
UPDATE [LOW_PRIORITY] [IGNORE] table_reference SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] ... [WHERE where_condition] [ORDER BY ...] [LIMIT row_count]多表更新语法
UPDATE [LOW_PRIORITY] [IGNORE] table_references SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] ... [WHERE where_condition]
注:
WHERE子句非常重要 , 所以不应该忘记指定更新的条件。 有时 , 您可能只想改变一行; 但是 , 可能会忘记写上WHERE子句 , 导致意外更新表中的所有行。避免没有添加
WHERE子句,更新数据库表格中所有行, 可利用mysql选项避免此错误。#连接时添加下面选项 mysql -U | --safe-updates | --i-am-a-dummy #直接在配置文件中添加如下内容 [root@centos7 etc]# cat /etc/my.cnf [mysql] safe-updates
在一条UPDATE语句中 , 如果要更新多个字段 , 字段间不能使用“AND” , 而应该用逗号分隔。
有问题的SQL语句 :
update apps set owner_code='43212' and owner_name='李四' where
owner_code='13245' and owner_name='张三'; 执行之前的记录是这样的:

执行之后的记录是这样的
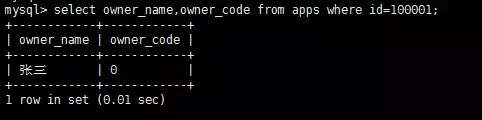
可以看到 , 结果并不像这位开发同学说的“好像没有效果” , 实际上是有效果的 :
owner_name的值没有变 , 但owner_code变成了0!
主要原因如下
update apps set owner_code='43212' and owner_name='李四' where
owner_code='13245' and owner_name='张三'; 等价于 :
update apps set owner_code=('43212' and owner_name='李四') where
owner_code='13245' and owner_name='张三'; 而('43212' and owner_name='李四')是一个逻辑表达式 , 而这里不难知道owner_name并不是'李四'。因此 , 这个逻辑表达式的结果为false , false在MySQL中等价于0!
3.1 使用UPDATE修改单列值
在这个例子中 , 我们将把 customer_id 等于 1 的客户的电子邮件修改为 NEW.MARY.SMITH@sakilacustomer.org。
使用以下
SELECT语句查看更新前的数据。SELECT first_name, last_name, email FROM customer WHERE customer_id = 1;+------------+-----------+-------------------------------+ | first_name | last_name | email | +------------+-----------+-------------------------------+ | MARY | SMITH | MARY.SMITH@sakilacustomer.org | +------------+-----------+-------------------------------+ 1 row in set (0.00 sec)使用以下
UPDATE语句更新email字段的值。UPDATE customer SET email = 'NEW.MARY.SMITH@sakilacustomer.org' WHERE customer_id = 1;Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0在此
UPDATE语句中 :通过
WHERE子句指定更新的条件为customer_id = 1。通过
SET子句将email列的值设置为新电子邮件。
在
UPDATE输出的结果中 :1 row affected表示 1 行数据受影响。也就是更新了 1 行数据。Rows matched: 1表示匹配的WHERE条件的行数是 1。Changed: 1表示修改的行数是 1。Warnings: 0表示没有需要注意的事项。
使用以下
SELECT语句查看更新后的数据 , 以验证是否更新成功。SELECT first_name, last_name, email FROM customer WHERE customer_id = 1;+------------+-----------+-----------------------------------+ | first_name | last_name | email | +------------+-----------+-----------------------------------+ | MARY | SMITH | NEW.MARY.SMITH@sakilacustomer.org | +------------+-----------+-----------------------------------+ 1 row in set (0.01 sec)
3.2 使用UPDATE修改多列值
在这个例子中 , 我们将同时更新 customer_id 等于 1 的客户的 first_name, last_name, email。
UPDATE customer
SET first_name = 'Tim',
last_name = 'Duncan',
email = 'Tim.Duncan@sakilacustomer.org'
WHERE customer_id = 1;然后 , 我们再次验证更新后的数 :
SELECT first_name, last_name, email
FROM customer
WHERE customer_id = 1;+------------+-----------+-------------------------------+
| first_name | last_name | email |
+------------+-----------+-------------------------------+
| Tim | Duncan | Tim.Duncan@sakilacustomer.org |
+------------+-----------+-------------------------------+
1 row in set (0.00 sec)3.3 使用表达式更新
使用 UPDATE 更新时 , 字段的值可以设置为表达式的运算结果 , 比如函数或其他的运算。
下面的 UPDATE 更新所有客户的电子邮件的域名部分 :
UPDATE customer
SET email = REPLACE(email, 'sakilacustomer.org', 'sjkjc.com');Query OK, 599 rows affected (0.03 sec)
Rows matched: 599 Changed: 599 Warnings: 0注意 , 本例中没有使用 WHERE 子句 , 所以表中所有的数据都进行了更新。
3.4 使用子查询更新
下面实例展示了如何为没有绑定商店的客户绑定一个随机商店。
UPDATE customer
SET store_id = (
SELECT store_id
FROM store
ORDER BY RAND()
LIMIT 1
)
WHERE store_id IS NULL;在本例中 , 我们通过以下 SELECT 语句返回一个随机的商店 id :
SELECT store_id
FROM store
ORDER BY RAND()
LIMIT 1在 SET 子句中 , 将 store_id 的值设置为上面的子查询。
3.5 多表更新(关联表更新)
在开发过程中 , 有时会遇到需要将某张表的字段值根据条件动态地更新到另一张表字段的问题 , 即通过一张表的字段修改另一张关联表中的内容。比如 , 存在两张表A(表名 : test_a)、B(表名 : test_b) , 他们的表结构如下 :
表A(test_a) :
表B(test_b) :
现在我们需要将表A的 dept_id 字段值根据 user_id 字段同步到表B的 dept_id 字段中 , 即用表A中的 dept_id 字段数据去更新表B中的dept_id 字段 , 条件是表A的user_id 字段值与表B的 user_id 字段值相等时进行更新。
在MySQL中我们有几种方法可以做到 :
方法一 :
UPDATE test_a a, test_b b
SET b.dept_id = a.dept_id
WHERE
b.user_id = a.user_id;方法二 : (通过 INNER JOIN)
UPDATE test_a a
INNER JOIN test_b b ON a.user_id = b.user_id
SET b.dept_id = a.dept_id;方法三 : (通过 LEFT JOIN)
UPDATE test_a a
LEFT JOIN test_b b ON a.user_id = b.user_id
SET b.dept_id = a.dept_id;方法四 : (通过子查询)
UPDATE test_b b
SET dept_id = ( SELECT dept_id FROM test_a WHERE user_id = b.user_id );上面的代码片断都是在两张表之间做关联 , 但只更新其中一张表的数据。其实 , 除了更新其中一张表的数据外 , 方法一、方法二和方法三是可以同时更新两张表的数据 , 如 :
SQL
-- 以下代码无实际意义 , 目的是方便记录
-- 方法一
UPDATE test_a a, test_b b
SET b.dept_id = a.dept_id, a.update_time = b.create_time
WHERE
b.user_id = a.user_id;
-- 方法二 : (通过 INNER JOIN)
UPDATE test_a a
INNER JOIN test_b b ON a.user_id = b.user_id
SET b.dept_id = a.dept_id, a.update_time = b.create_time;
-- 方法三 : (通过 LEFT JOIN)
UPDATE test_a a
LEFT JOIN test_b b
ON a.user_id = b.user_id
SET b.dept_id = a.dept_id, a.update_time = b.create_time;4. DELETE 语句
删除表中数据,但不会自动缩减数据文件的大小。
语法
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count] 可先排序再指定删除的行数注意 :
WHERE子句是可选的。如果省略WHERE子句 ,DELETE语句将删除表中的所有行。
4.1 单表删除
4.1.1 根据条件删除实例
删除
actor_id等于1的行DELETE FROM actor_copy WHERE actor_id = 1;Query OK, 1 row affected (0.00 sec)删除
last_name等于KILMER的行DELETE FROM actor_copy WHERE last_name = 'KILMER';Query OK, 5 rows affected (0.01 sec)
4.1.2 限制删除的最大行数
考虑以下这些需求 :
删除排名最靠后的 5 个成绩
删除最新注册的 10 名用户
这时 , 我们可以结合使用 ORDER BY 和 LIMIT 子句。
以下语句用来删除 actor_copy 中 actor_id 最大的 10 行 :
DELETE FROM actor_copy
ORDER BY actor_id DESC
LIMIT 10;Query OK, 10 rows affected (0.01 sec)如果单独使用 LIMIT 子句 , 删除的顺序是不明确的。大多数情况下 , DELETE 语句中的 LIMIT 子句都应该和 ORDER BY 子句一起使用。
4.1.3 删除表中所有行
如果我们不在 DELETE 语句中使用 WHERE 或者 LIMIT 子句 , 则会删除表中的所有行。
DELETE FROM actor_copy;Query OK, 185 rows affected (0.00 sec)我们通过以下语句检查表中是否还有数据行 :
SELECT COUNT(*) FROM actor_copy;+----------+
| COUNT(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)此时 , actor_copy 表已经空了。
如果你只是想清空表 , 可以使用 TRUNCATE TABLE语句以获得更好的性能。如下 :
TRUNCATE actor_copy;4.2 DELETE 表别名
在早期的MySQL版本中 , 单表删除 DELETE 语句不支持为表设置别名。比如 :
DELETE FROM main_table m
WHERE NOT EXISTS (
SELECT *
FROM another_table a
WHERE a.main_id = m.id
);将会产生错误 : Error Code: 1064. You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 't' at line 1 0.016 sec。
可以改成如下语句:
DELETE m FROM main_table m
WHERE NOT EXISTS (
SELECT *
FROM another_table a
WHERE a.main_id = m.id
);或者不使用别名 , 而是使用表名 :
DELETE FROM main_table
WHERE NOT EXISTS (
SELECT *
FROM another_table a
WHERE a.main_id = main_table.id
);4.3 多表删除
4.3.1 MySQL delete join语句
我们也可以在一个 DELETE 语句中指定多个表 , 以便在一个或多个表中删除符合 WHERE 子句中的条件的行。
以下语句删除
t1和t2表中满足条件的行 :DELETE t1, t2 FROM t1 INNER JOIN t2 WHERE t1.id = t2.id;以下语句删除
t1表中满足条件的行 :DELETE t1 FROM t1 INNER JOIN t2 WHERE t1.id = t2.id;以下语句在删除时使用
LEFT JOIN:DELETE t1 FROM t1 LEFT JOIN t2 ON t1.id = t2.id WHERE t2.id IS NULL;
只要是 SELECT 语句中允许使用的 JOIN 类型 , 多表删除语句都可以使用。
多表删除语句中不能使用 LIMIT 子句和 ORDER BY 子句。
4.3.2 MySQL on delete cascade
下面来看一些使用MySQL ON DELETE CASCADE的例子。
假设有两张表 : 建筑物(buildings)和房间(rooms)。 在这个数据库模型中 , 每个建筑物都有一个或多个房间。 然而 , 每个房间只属于一个建筑物。没有建筑物则房间是不会存在的。
建筑物和房间表之间的关系是一对多(1:N) , 如下面的数据库图所示:

当我们从buildings表中删除一行时 , 还要删除rooms表中引用建筑物表中行的行。 例如 , 当删除建筑编号(building_no)为2的行记录时 , 在buildings表上执行如下查询 :
DELETE FROM buildings
WHERE
building_no = 2;我们希望rooms表中涉及到建筑物编号2的行记录也将被删除(讲得通俗一点 : 假设2号楼倒塌了 , 那么2号楼的房间应该也就不存在了)。以下是演示MySQL ON DELETE CASCADE参考操作如何工作的步骤。
第一步 , 创建
buildings表 , 如下创建语句:USE testdb; CREATE TABLE buildings ( building_no INT PRIMARY KEY AUTO_INCREMENT, building_name VARCHAR(255) NOT NULL, address VARCHAR(255) NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8;第二步 , 创建
rooms表 , 如下创建语句:USE testdb; CREATE TABLE rooms ( room_no INT PRIMARY KEY AUTO_INCREMENT, room_name VARCHAR(255) NOT NULL, building_no INT NOT NULL, FOREIGN KEY (building_no) REFERENCES buildings (building_no) ON DELETE CASCADE )ENGINE=InnoDB DEFAULT CHARSET=utf8;请注意 , 在外键约束定义的末尾添加
ON DELETE CASCADE子句。第三步 , 将一些数据插入到
buildings表 , 如下插入语句:INSERT INTO buildings(building_name,address) VALUES('海南大厦','海口市国兴大道1234号'), ('万达水城','海口市大同路1200号');第四步 , 查询
buildings表中的数据 :mysql> select * from buildings; +-------------+---------------+----------------------+ | building_no | building_name | address | +-------------+---------------+----------------------+ | 1 | 海南大厦 | 海口市国兴大道1234号 | | 2 | 万达水城 | 海口市大同路1200号 | +-------------+---------------+----------------------+ 2 rows in set现在可以看到 , 在建筑物表中有两行记录。
第五步 , 将一些数据插入到
rooms表 , 如下插入语句:INSERT INTO rooms(room_name,building_no) VALUES('Amazon',1), ('War Room',1), ('Office of CEO',1), ('Marketing',2), ('Showroom',2);第六步 , 查询
rooms表中的数据 :mysql> select * from rooms; +---------+---------------+-------------+ | room_no | room_name | building_no | +---------+---------------+-------------+ | 1 | Amazon | 1 | | 2 | War Room | 1 | | 3 | Office of CEO | 1 | | 4 | Marketing | 2 | | 5 | Showroom | 2 | +---------+---------------+-------------+ 5 rows in set从上面行记录中可以看到 ,
building_no=1的建筑有3个房间 , 以及building_no=2有2个房间。第七步 , 删除编号为
2的建筑物:DELETE FROM buildings WHERE building_no = 2;第八步 , 查询
rooms表中的数据 -mysql> DELETE FROM buildings WHERE building_no = 2; Query OK, 1 row affected mysql> SELECT * FROM rooms; +---------+---------------+-------------+ | room_no | room_name | building_no | +---------+---------------+-------------+ | 1 | Amazon | 1 | | 2 | War Room | 1 | | 3 | Office of CEO | 1 | +---------+---------------+-------------+ 3 rows in set可以看到 , 表中只剩下引用
building_no=1的记录了 , 引用building_no=2的所有行记录都被自动删除了。
请注意 ,
ON DELETE CASCADE仅支持使用存储引擎支持外键(如InnoDB)的表上工作。 某些表类型不支持诸如MyISAM的外键 , 因此应该在使用MySQLON DELETE CASCADE引用操作的表上选择适当的存储引擎。
查找受MySQL ON DELETE CASCADE操作影响的表的技巧
有时 , 当要从表中删除数据时 , 知道哪个表受到MySQL ON DELETE CASCADE参考操作的影响是有用的。 可从information_schema数据库中的referential_constraints表中查询此数据 , 如下所示 :
USE information_schema;
SELECT
table_name
FROM
referential_constraints
WHERE
constraint_schema = 'database_name'
AND referenced_table_name = 'parent_table'
AND delete_rule = 'CASCADE'例如 , 要使用示例数据库(testdb , 因为上面两个表是建立在testdb数据库之上的)中的CASCADE删除规则查找与建筑表相关联的表 , 请使用以下查询 :
USE information_schema;
SELECT
table_name
FROM
referential_constraints
WHERE
constraint_schema = 'testdb'
AND referenced_table_name = 'buildings'
AND delete_rule = 'CASCADE'执行上面查询语句 , 得到以下结果 -
+------------+
| table_name |
+------------+
| rooms |
+------------+
1 row in set4.4 表空间收缩
使用重建表的方式可以收缩表空间 , 重建表有以下三种方式:
alter table t engine=InnoDB
optmize table t
truncate table t重建表过程
建立一个临时文件 ,扫描表 t 主键的所有数据页;
用数据页中表 t 的记录生成 B+ 树 , 存储到临时文件中;
生成临时文件的过程中 , 将所有对 t 的操作记录在一个日志文件(row log)中;
临时文件生成后 , 将日志文件中的操作应用到临时文件 , 得到一个逻辑数据上与表 t相同的数据文件;
用临时文件替换表 t 的数据文件。
4.4.1 TRUNCATE
如果想清空表,保留表结构,也可以使用下面语句, 次语句会自动缩减文件的大小。
TRUNCATE TABLE tbl_name; #语句相当于先将此表删除掉 , 再创建一个新表。虽然 TRUNCATE 与 DELETE 类似 , 但是他们在以下几个方面存在不同 :
TRUNCATE被归类为DDL语句 , 而DELETE被归类为DML语句。TRUNCATE操作无法被回滚 , 而DELETE可以被回滚。TRUNCATE操作删除和重建表 , 它的速度比DELETE快得多。TRUNCATE操作会重置表的自增值 , 而DELETE不会。TRUNCATE操作不会激活删除触发器 , 而DELETE会。TRUNCATE操作不返回代表删除行的数量的值 , 它通常返回0 rows affected。DELETE返回删除的行数。如果一个表被其他表的外键引用 , 对此表的
TRUNCATE操作会失败。
4.4.2 OPTIMIZE
共享表空间 : 指的是数据库的所有的表数据 , 索引文件全部放在一个文件中 , 默认这个共享表空间的文件路径在 data 目录下。 独立表空间 : 每一个表都将会生成以独立的文件方式来进行存储。 共享表空间和独立表空间最大的区别是如果把表放再共享表空间 , 即使表删除了空间也不会删除 , 所以表依然很大 , 而独立表空间如果删除表就会清除空间
当对MySQL进行大量的增删改操作的时候 , 很容易产生一些碎片 , 这些碎片占据着空间 , 所以可能会出现删除很多数据后 , 数据文件大小变化不大的现象。当然新插入的数据仍然会利用这些碎片。但过多的碎片 , 对数据的插入操作是有一定影响的 , 此时 , 我们可以通过optimize来对表的优化。
OPTIMIZE TABLE tbl_name;针对MySQL的不同数据库存储引擎 , 在optimize使用清除碎片,回收闲置的数据库空间 ,把分散存储(fragmented) 的数据和索引重新挪到一起(defragmentation) , 对I/O速度有好处。 当然optimize在对表进行操作的时候 , 会加锁 , 所以不宜经常在程序中调用。
使用命令show table status [like table_name]来查看数据碎片。
MariaDB [testdb]> show table status like 'buildings'\G;
*************************** 1. row ***************************
Name: buildings
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 1
Avg_row_length: 16384
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 3
Create_time: 2023-02-21 13:40:50
Update_time: 2023-02-21 13:42:44
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
Max_index_length: 0
Temporary: N
1 row in set (0.003 sec)
#其中data_free代表数据碎片InnoDB引擎的表分为独享表空间和同享表空间的表 , 我们可以通过show variables like 'innodb_file_per_table'; 来查看是否开启独享表空间。我本地是开启了独享表空间的。此时是无法对表进行optimize 操作的 , 如果操作 , 会返回如图信息 , 最后的一条Table does not support optimize, doing recreate + analyze instead1。因为当表删除或者truncate , 空间可以被OS回收。
针对MyISAM表 , 直接使用如下命令进行优化optimize table table1[,table2][,table3]。如果同时优化多个表可以使用逗号分隔。可以看出 , 优化后data_free值为0。

