
1. VIEW视图
MySQL中的视图(view)是一种虚拟表 , 其内容由查询定义 , 是一个逻辑表 , 本身并不包含数据。视图看起来和真实的表完全相同 , 但其中的数据来自定义视图时用到的基本表 , 并且在打开视图时动态生成。
视图可以在基本表上定义 , 也可以使用其他视图定义。与直接操作基本表相比 , 视图具备以下优点 :
简化操作 : 通过视图可以使用户将注意力集中在他所关心的数据上。使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件。
提高数据的安全性 : 在设计数据库时可以针对不同的用户定义不同的视图 , 使用视图的用户只能访问他们被允许查询的结果集。
数据独立 : 视图的结构定义好之后 , 如果增加新的关系或对原有的关系增加新的字段对用户访问的数据都不会造成影响。
创建方法 :
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]OR REPLACE: 表示该语句能够替换已有视图;ALGORITHM: 可选参数 , 表示视图选择的算法 , 默认算法是UNDEFINED;view_name: 要创建的视图名称;column_list: 可选参数 , 表示视图的字段列表。如果省略 , 则使用select语句中的字段列表 ;AS select_statement: 创建视图的select语句 ;WITH CHECK OPTION: 表示更新视图时要保证该视图的WHERE子句为【真】。比如 : 定义视图create view v1 as select * from salary>5000;如果要更新视图 , 则必须保证salary字段的值在5000以上 , 否则报错;
查看视图定义
SHOW CREATE VIEW view_name #只能看视图定义 SHOW CREATE TABLE view_name # 可以查看表和视图删除视图
DROP VIEW [IF EXISTS] view_name [, view_name] ... [RESTRICT | CASCADE]修改视图
Alter [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]
注意 : 视图中的数据事实上存储于“基表”中 , 因此 , 其修改操作也会针对基表实现 ; 其修改操作受基表限制
范例 :
#创建视图
MariaDB [hellodb]> create view v_st_co_sc as select st.name,co.Course,sc.score
from students st inner join scores sc on st.stuid=sc.stuid inner join courses co
on sc.courseid=co.CourseID;
MariaDB [hellodb]> SHOW TABLE STATUS LIKE 'v_st_co_sc'\G
*************************** 1. row ***************************
Name: v_st_co_sc
Engine: NULL
Version: NULL
Row_format: NULL
Rows: NULL
Avg_row_length: NULL
Data_length: NULL
Max_data_length: NULL
Index_length: NULL
Data_free: NULL
Auto_increment: NULL
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: NULL
Checksum: NULL
Create_options: NULL
Comment: VIEW
Max_index_length: NULL
Temporary: NULL
1 row in set (0.001 sec)
MariaDB [hellodb]> show create view v_st_co_sc\G;
*************************** 1. row ***************************
View: v_st_co_sc
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `v_st_co_sc` AS select `st`.`Name` AS `name`,`co`.`Course` AS `Course`,`sc`.`Score` AS `score` from ((`students` `st` join `scores` `sc` on(`st`.`StuID` = `sc`.`StuID`)) join `courses` `co` on(`sc`.`CourseID` = `co`.`CourseID`))
character_set_client: utf8
collation_connection: utf8_general_ci
1 row in set (0.000 sec)
ERROR: No query specified
#修改视图, 最后加了order by sc.score;语句
MariaDB [hellodb]> alter view v_st_co_sc as select st.name,co.Course,sc.score from students st inner join scores sc on st.stuid=sc.stuid inner join courses co on sc.courseid=co.CourseID order by sc.score;
Query OK, 0 rows affected (0.001 sec)
MariaDB [hellodb]> select * from v_st_co_sc;
+-------------+----------------+-------+
| name | Course | score |
+-------------+----------------+-------+
| Yu Yutong | Hamo Gong | 39 |
| Shi Potian | Kuihua Baodian | 47 |
| Lin Daiyu | Taiji Quan | 57 |
| Yu Yutong | Dagou Bangfa | 63 |
| Ding Dian | Daiyu Zanghua | 71 |
| Xie Yanke | Weituo Zhang | 75 |
| Shi Zhongyu | Kuihua Baodian | 77 |
| Xi Ren | Dagou Bangfa | 83 |
| Xi Ren | Hamo Gong | 86 |
| Xie Yanke | Kuihua Baodian | 88 |
| Ding Dian | Kuihua Baodian | 89 |
| Shi Zhongyu | Weituo Zhang | 93 |
| Lin Daiyu | Jinshe Jianfa | 93 |
| Shi Qing | Hamo Gong | 96 |
| Shi Potian | Daiyu Zanghua | 97 |
+-------------+----------------+-------+
15 rows in set (0.001 sec)
2. FUNCTION函数
函数 : 分为系统内置函数和自定义函数
系统内置函数参考:
https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html
自定义函数,
user-defined function(UDF) : 是一种对MySQL扩展的途径 , 其用法和内置函数相同。保存在mysql.proc表中 。
2.1 内置函数
1、数学函数
ABS(x) --返回x的绝对值
BIN(x) --返回x的二进制(OCT返回八进制 , HEX返回十六进制)
CEILING(x) --返回大于x的最小整数值
EXP(x) --返回值e(自然对数的底)的x次方
FLOOR(x) --返回小于x的最大整数值
GREATEST(x1,x2,...,xn)
--返回集合中最大的值
LEAST(x1,x2,...,xn)
--返回集合中最小的值
LN(x) --返回x的自然对数
LOG(x,y) --返回x的以y为底的对数
MOD(x,y) --返回x/y的模(余数)
PI() --返回pi的值(圆周率)
RAND() --返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
ROUND(x,y) --返回参数x的四舍五入的有y位小数的值
SIGN(x) --返回代表数字x的符号的值
SQRT(x) --返回一个数的平方根
TRUNCATE(x,y) --返回数字x截短为y位小数的结果2、聚合函数
AVG(X) --返回指定列的平均值
COUNT(X) --返回指定列中非NULL值的个数
MIN(X) --返回指定列的最小值
MAX(X) --返回指定列的最大值
SUM(X) --返回指定列的所有值之和
GROUP_CONCAT(X) --返回由属于一组的列值连接组合而成的结果 , 非常有用3、字符串函数
ASCII(char) --返回字符的ASCII码值
BIT_LENGTH(str) --返回字符串的比特长度
CONCAT(s1,s2...,sn)
--将s1,s2...,sn连接成字符串
CONCAT_WS(sep,s1,s2...,sn)
--将s1,s2...,sn连接成字符串 , 并用sep字符间隔
INSERT(str,x,y,instr)
--将字符串str从第x位置开始 , y个字符长的子串替换为字符串instr , 返回结果
FIND_IN_SET(str,list)
--分析逗号分隔的list列表 , 如果发现str , 返回str在list中的位置
LCASE(str)或LOWER(str)
--返回将字符串str中所有字符改变为小写后的结果
LEFT(str,x) --返回字符串str中最左边的x个字符
LENGTH(s) --返回字符串str中的字符数
LTRIM(str) --从字符串str中切掉开头的空格
POSITION(substr,str)
--返回子串substr在字符串str中第一次出现的位置
QUOTE(str) --用反斜杠转义str中的单引号
REPEAT(str,srchstr,rplcstr)
--返回字符串str重复x次的结果
REVERSE(str) --返回颠倒字符串str的结果
RIGHT(str,x) --返回字符串str中最右边的x个字符
RTRIM(str) --返回字符串str尾部的空格
STRCMP(s1,s2) --比较字符串s1和s2
TRIM(str) --去除字符串首部和尾部的所有空格
UCASE(str)或UPPER(str)
--返回将字符串str中所有字符转变为大写后的结果4、日期和时间函数
CURDATE()或CURRENT_DATE()
--返回当前的日期
CURTIME()或CURRENT_TIME()
--返回当前的时间
DATE_ADD(date,INTERVAL int keyword)
--返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化)
例如
SELECT DATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH);
DATE_FORMAT(date,fmt)
--依照指定的fmt格式格式化日期date值
DATE_SUB(date,INTERVAL int keyword)
--返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化)
例如
SELECT DATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH);
DAYOFWEEK(date) --返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) --返回date是一个月的第几天(1~31)
DAYOFYEAR(date) --返回date是一年的第几天(1~366)
DAYNAME(date) --返回date的星期名 , 如 : SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt)
--根据指定的fmt格式 , 格式化UNIX时间戳ts
HOUR(time) --返回time的小时值(0~23)
MINUTE(time) --返回time的分钟值(0~59)
MONTH(date) --返回date的月份值(1~12)
MONTHNAME(date) --返回date的月份名 , 如 : SELECT MONTHNAME(CURRENT_DATE);
NOW() --返回当前的日期和时间
QUARTER(date) --返回date在一年中的季度(1~4)
例如
SELECT QUARTER(CURRENT_DATE);
WEEK(date) --返回日期date为一年中第几周(0~53)
YEAR(date) --返回日期date的年份(1000~9999)
例如 , 获取当前系统时间
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP());
SELECT EXTRACT(YEAR_MONTH FROM CURRENT_DATE);
SELECT EXTRACT(DAY_SECOND FROM CURRENT_DATE);
SELECT EXTRACT(HOUR_MINUTE FROM CURRENT_DATE);
返回两个日期值之间的差值(月数)
SELECT PERIOD_DIFF(200302,199802);
在Mysql中计算年龄 :
SELECT DATE_FORMAT(FROM_DAYS(TO_DAYS(NOW())-TO_DAYS(birthday)),'%Y')+0 AS age FROM employee;
这样 , 如果Brithday是未来的年月日的话 , 计算结果为0。
下面的SQL语句计算员工的绝对年龄 , 即当Birthday是未来的日期时 , 将得到负值。
SELECT DATE_FORMAT(NOW(), '%Y')
- DATE_FORMAT(birthday, '%Y')
-(DATE_FORMAT(NOW(), '00-%m-%d')
< DATE_FORMAT(birthday, '00-%m-%d')) AS age from employee5、加密函数
AES_ENCRYPT(str,key)
--返回用密钥key对字符串str利用高级加密标准算法加密后的结果 , 调用AES_ENCRYPT的结果是一个二进制字符串 , 以BLOB类型存储
AES_DECRYPT(str,key)
--返回用密钥key对字符串str利用高级加密标准算法解密后的结果
DECODE(str,key) --使用key作为密钥解密加密字符串str
ENCRYPT(str,salt) --使用UNIXcrypt()函数 , 用关键词salt(一个可以惟一确定口令的字符串 , 就像钥匙一样)加密字符串str
ENCODE(str,key) --使用key作为密钥加密字符串str , 调用ENCODE()的结果是一个二进制字符串 , 它以BLOB类型存储
MD5() --计算字符串str的MD5校验和
PASSWORD(str) --返回字符串str的加密版本 , 这个加密过程是不可逆转的 , 和UNIX密码加密过程使用不同的算法。
SHA() --计算字符串str的安全散列算法(SHA)校验和
例如
SELECT ENCRYPT('root','salt');
SELECT ENCODE('xufeng','key');
SELECT DECODE(ENCODE('xufeng','key'),'key');#加解密放在一起
SELECT AES_ENCRYPT('root','key');
SELECT AES_DECRYPT(AES_ENCRYPT('root','key'),'key');
SELECT MD5('123456');
SELECT SHA('123456');6、控制流函数
CASE WHEN [test1] THEN [result1]...ELSE [default] END
--如果test1是真 , 则返回result1 , 否则返回default
CASE [test] WHEN [val1] THEN [result]...ELSE [default] END
--如果test和valN相等 , 则返回result , 否则返回default
IF(test,t,f) --如果test是真 , 返回t;否则返回f
IFNULL(arg1,arg2) --如果arg1不是空 , 返回arg1 , 否则返回arg2
NULLIF(arg1,arg2) --如果arg1=arg2返回NULL;否则返回arg1
这些函数的第一个是IFNULL() , 它有两个参数 , 并且对第一个参数进行判断。
如果第一个参数不是NULL , 函数就会向调用者返回第一个参数;
如果是NULL,将返回第二个参数。
例如
SELECT IFNULL(1,2),
IFNULL(NULL,10),
IFNULL(4*NULL,'false');
NULLIF()函数将会检验提供的两个参数是否相等 , 如果相等 , 则返回NULL ,
如果不相等 , 就返回第一个参数。
例如
SELECT NULLIF(1,1),
NULLIF('A','B'),
NULLIF(2+3,4+1);
MySQL的IF()函数也可以建立一个简单的条件测试 ,
这个函数有三个参数 , 第一个是要被判断的表达式 ,
如果表达式为真 , IF()将会返回第二个参数 ,
如果为假 , IF()将会返回第三个参数。
例如
SELECT IF(1<10,2,3),IF(56>100,'true','false');
IF()函数在只有两种可能结果时才适合使用。
然而 , 在现实世界中 , 我们可能发现在条件测试中会需要多个分支。
在这种情况下 , 它和PHP及Perl语言的switch-case条件例程一样。
CASE函数的格式有些复杂 , 通常如下所示 :
CASE [expression to be evaluated]
WHEN [val 1] THEN [result 1]
WHEN [val 2] THEN [result 2]
WHEN [val 3] THEN [result 3]
......
WHEN [val n] THEN [result n]
ELSE [default result]
END
这里 , 第一个参数是要被判断的值或表达式 , 接下来的是一系列的WHEN-THEN块 ,
每一块的第一个参数指定要比较的值 , 如果为真 , 就返回结果。
所有的WHEN-THEN块将以ELSE块结束 , 当END结束了所有外部的CASE块时 ,
如果前面的每一个块都不匹配就会返回ELSE块指定的默认结果。
如果没有指定ELSE块 , 而且所有的WHEN-THEN比较都不是真 , MySQL将会返回NULL。
CASE函数还有另外一种句法 , 有时使用起来非常方便 , 如下 :
CASE
WHEN [conditional test 1] THEN [result 1]
WHEN [conditional test 2] THEN [result 2]
ELSE [default result]
END
这种条件下 , 返回的结果取决于相应的条件测试是否为真。
例如 :
SELECT CASE 'green'
WHEN 'red' THEN 'stop'
WHEN 'green' THEN 'go' END;
SELECT CASE 9
WHEN 1 THEN 'a'
WHEN 2 THEN 'b' ELSE 'N/A' END;
SELECT CASE WHEN (2+2)=4 THEN 'OK'
WHEN (2+2)<>4 THEN 'not OK' END AS STATUS;
SELECT Name,IF((IsActive = 1),'已激活','未激活') AS RESULT
FROM UserLoginInfo;
SELECT fname,lname,(math+sci+lit) AS total,
CASE WHEN (math+sci+lit) < 50 THEN 'D'
WHEN (math+sci+lit) BETWEEN 50 AND 150 THEN 'C'
WHEN (math+sci+lit) BETWEEN 151 AND 250 THEN 'B'
ELSE 'A' END AS grade FROM marks;
SELECT IF(ENCRYPT('sue','ts')=upass,'allow','deny') AS LoginResult
FROM users WHERE uname = 'sue';7、格式化函数
DATE_FORMAT(date,fmt)
--依照字符串fmt格式化日期date值
FORMAT(x,y) --把x格式化为以逗号隔开的数字序列 , y是结果的小数位数
INET_ATON(ip) --返回IP地址的数字表示
INET_NTOA(num) --返回数字所代表的IP地址
TIME_FORMAT(time,fmt)
--依照字符串fmt格式化时间time值
其中最简单的是FORMAT()函数 ,
它可以把大的数值格式化为以逗号间隔的易读的序列。
例如
SELECT FORMAT(34234.34323432,3);
SELECT DATE_FORMAT(NOW(),'%W,%D %M %Y %r');
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d');
SELECT DATE_FORMAT(19990330,'%Y-%m-%d');
SELECT DATE_FORMAT(NOW(),'%h:%i %p');
SELECT INET_ATON('10.122.89.47');
SELECT INET_NTOA(175790383);8、类型转化函数
为了进行数据类型转化 , MySQL提供了CAST()函数 ,
它可以把一个值转化为指定的数据类型。
类型有 : BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED
例如
SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0;
SELECT 'f'=BINARY 'F','f'=CAST('F' AS BINARY);9、系统信息函数
DATABASE() --返回当前数据库名
BENCHMARK(count,expr)
--将表达式expr重复运行count次
CONNECTION_ID() --返回当前客户的连接ID
FOUND_ROWS() --返回最后一个SELECT查询进行检索的总行数
USER()或SYSTEM_USER()
--返回当前登陆用户名
VERSION() --返回MySQL服务器的版本
例如
SELECT DATABASE(),VERSION(),USER();
SELECTBENCHMARK(9999999,LOG(RAND()*PI()));#
该例中,MySQL计算LOG(RAND()*PI())表达式9999999次。2.2 自定义函数
2.2.1 SQL语句定义函数
2.2.1.1 基本语法
语法
CREATE FUNCTION 函数名(参数名 参数类型,...) RETURNS 返回值类型 BEGIN 函数体 #函数体中肯定有 RETURN 语句 函数体中可以包含以下内容 declare 变量名 变量类型; 逻辑语句; return 返回值; END CREATE [OR REPLACE] [DEFINER = {user | CURRENT_USER | role | CURRENT_ROLE }] [AGGREGATE] FUNCTION [IF NOT EXISTS] func_name ([func_parameter[,...]]) RETURNS type [characteristic ...] RETURN func_body func_parameter: [ IN | OUT | INOUT | IN OUT ] param_name type type: Any valid MariaDB data type characteristic: LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string' func_body: Valid SQL procedure statement
说明:
参数可以有多个也可以没有参数
无论有无参数,
function_name后面的小括号()是必须的必须有且只有一个返回值
为避免和函数中的语句结束符
;冲突,将语句结束符号临时重定义为$$delimiter $$函数体也可以用
BEGIN…END来表示SQL代码的开始和结束。如果函数体只有一条语句 , 也可以省略BEGIN…END。mysql用户自定义函数返回值不支持表类型 , 改用存储过程
查看函数列表 :
SHOW FUNCTION STATUS; 查看函数定义
SHOW CREATE FUNCTION function_name修改函数定义: 函数的修改只能修改一些如comment的选项 , 不能修改内部的sql语句和参数列表。
ALTER FUNCTION 函数名 选项;删除UDF
DROP FUNCTION [IF EXISTS] function_name调用自定义函数语法
SELECT function_name(parameter_value,...)范例:
#无参UDF
CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World";
#有参数UDF
DELIMITER //
CREATE FUNCTION delete ById(id SMALLINT UNSIGNED) RETURNS VARCHAR(20)
BEGIN
DELETE FROM students WHERE stuid = id;
RETURN (SELECT COUNT(*) FROM students);
END//
DELIMITER;2.2.1.2 MySQL变量使用
MYSQL 中的变量
两种变量: 系统内置变量和用户自定义变量
系统变量 :
MySQL数据库中内置的变量 , 可用@@var_name引用用户自定义变量分为以下两种
普通变量 : 在当前会话中有效, 可用
@var_name引用局部变量 : 在函数或存储过程内才有效,需要用
DECLARE声明, 之后直接用var_name引用
自定义函数中定义局部变量语法
DECLARE 变量1[,变量2,...]变量类型 [DEFAULT 默认值] 函数中可以通过 declare 声明定义局部变量 , 其作用域为begin ... end的函数体中。默认初值为null , 可以通过default指定该语句中所有定义变量的初值
说明: 局部变量的作用范围是在BEGIN...END程序中,而且定义局部变量语句必须在BEGIN...END的第一行定义
范例:
DELIMITER //
CREATE FUNCTION addTwoNumber(x SMALLINT UNSIGNED, y SMALLINT UNSIGNED)
RETURNS SMALLINT
BEGIN
DECLARE a, b SMALLINT UNSIGNED;
SET a = x, b = y;
RETURN a+b;
END//
DELIMITER ;
MariaDB [hellodb]> select addTwoNumber( 1 ,2 );
+----------------------+
| addTwoNumber( 1 ,2 ) |
+----------------------+
| 3 |
+----------------------+
1 row in set (0.001 sec)为变量赋值语法
使用
SET给局部变量赋值set var = expression [, var = expression, ...]; set var := expression [, var = expression, ...]; SET parameter_name = value[,parameter_name = value...]注 :
sql下的=操作符是比较(判定是否相等)操作符, 只有在set语句中可作为赋值操作符使用。故在其他语句中 ,赋值操作应该使用:=操作符使用
SET命令给普通变量赋值set @varName = val; # 对名为 @varName 用户变量赋值 set @varName := val; # 对名为 @varName 用户变量赋值 select @varName; # 查看名为 @varName 用户变量的值通过
SELECT INTO给局部变量赋值通过
select语句将所查询出的字段数据依次赋值到into后的变量中。值得一提的是 , 当select查询结果为空时(即 , 无记录) , 则不对变量进行赋值操作 ; 当select查询的结果不止一条时 ,MySQL将报错 , 函数执行失败select filed1 [, ...] into var1 [, ...] from tableName where conditon通过
SELECT INTO给普通变量赋值, 需要注意的是 , 只能使用:=操作符赋值select @varName:=field [as field] [, ...] from tableName where condition; select @varName:=Val;
范例:
.....
DECLARE x int;
SELECT COUNT(*) FROM tdb_name INTO x ;
RETURN x;
END// 范例: 自定义的普通变量
MariaDB [hellodb]> select count(*) from students into @num;
Query OK, 1 row affected (0.000 sec)
MariaDB [hellodb]> select @num;
+------+
| @num |
+------+
| 24 |
+------+
1 row in set (0.000 sec)范例:
create
function myfunTest(idx int)
returns int
comment '测试函数'
begin
declare res int; # 声明定义1个变量, 初值默认为 null
declare num1, num2 int default 27; # 声明定义多个变量 , 初值全部为27
declare data1, data2 int; # 声明定义多个变量 , 初值全部默认为 null
set num2 = 23, res = num1 + num2; # 使用set语句, = 操作符赋值
set data1 = 1, data2 = 1;
select num, price into data1, data2 from test2 where id = idx; # 使用 select into 语句
set res := res * (data1 + data2); # 使用set语句, := 操作符赋值
return (res);
end;结果演示
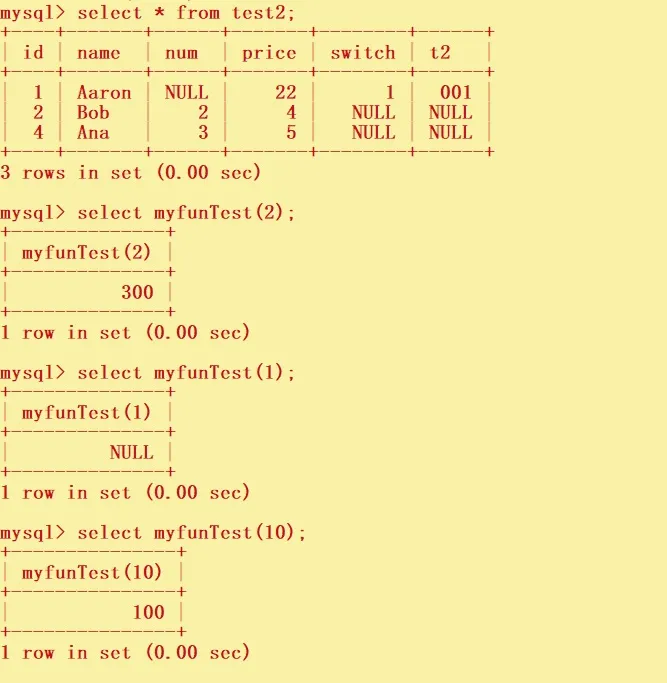
范例 :
-- 随机产生字符串
drop function if exists rand_string; -- 先判断是否已存在同名函数 , 如果已存在则先删除
DELIMITER $$ -- 两个 $$ 表示结束
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str = concat(return_str, substring(chars_str, floor(1+rand()*52), 1));
set i=i+1;
end while;
return return_str;
end $$
DELIMITER ;
-- 随机生成编号
drop function if exists rand_num;
DELIMITER $$
create function rand_num()
returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*10);
return i;
end $$
DELIMITER ;结果显示 :
MariaDB [hellodb]> select rand_string(5);
+----------------+
| rand_string(5) |
+----------------+
| EDbyl |
+----------------+
1 row in set (0.001 sec)
MariaDB [hellodb]> select rand_num();
+------------+
| rand_num() |
+------------+
| 107 |
+------------+
1 row in set (0.000 sec)2.2.2 动态库文件定义函数
语法
CREATE [OR REPLACE] [AGGREGATE] FUNCTION [IF NOT EXISTS] function_name RETURNS {STRING|INTEGER|REAL|DECIMAL} SONAME shared_library_name
在MySQL中 , 可以通过UDF扩充MySQL的功能 , 加入一个新的SQL函数类似于内置的函数(如 , ABS()or CONCAT()等。UDF使用C/C++实现 , 编译成动态库文件(Linux对应.so文件) , 可以使用CREATE FUNCTION动态加载到mysqld服务进程里 , 使用DROP FUNCTION从mysqld服务进程里移除。本文在MySQL 8.0上首先对MySQL UDF的接口进行了介绍 , 然后给出了一个简单的例子。 通过使用UDF :
可以返回
string,integer或real类型的值或作为函数参数能够定义简单函数或聚集函数(
aggregate function) , 本文只讲解简单函数 , 聚集函数请参考MySQL用户手册
2.2.2.1 如何实现MySQL UDF
MySQL UDF必须使用C/C++实现 , 同时要求操作系统必须支持动态装载 , 如果使用了mysqld中已经存在的符号 , 那么链接动态库的时候必须得使用链接选项 -rdynamic。
2.2.2.1.1 UDF 接口
为了定义UDF , 需要为每个UDF生成对应C/C++函数 , 为了下文描述方便 , 我们用“xxx”表示函数名 , 用大写的XXX()表示一个SQL函数调用 , 用小写的xxx()表示一个C/C++函数。下面是实现一个SQL函数XXX()所需要定义的C/C++函数。
2.2.2.1.1.1 xxx()
主函数 , 在SQL调用函数XXX()时最终会调用到这里 , SQL的数据类型和C/C++的数据类型对应关系如下:
这些数据类型用于函数的返回值和函数参数。
函数定义如下 :
对于SQL函数的返回值是STRING的 (这个函数原型同样适用于SQL函数返回类型是DECIMAL)
char * xxx(UDF_INIT *initid, UDF_ARGS *args,
char *result, unsigned long *length,
char *is_null, char *error);对于返回值是INTEGER的
long long xxx(UDF_INIT *initid, UDF_ARGS *args,
char *is_null, char *error);对于返回值是REAL的
double xxx(UDF_INIT *initid, UDF_ARGS *args,
char *is_null, char *error);2.2.2.1.1.2 xxx_init()
xxx()函数的初始化函数 , 这个函数的作用包括:
检查传入
XXX()函数的参数个数检验传入
XXX()的参数的数据类型 , 而且它还可以让MySQL将传入XXX()的参数转成xxx()需要的数据类型分配
xxx()函数需要的内存指定返回值的最大长度
指定返回值是
REAL的函数的返回值的精度指定返回值是不是
NULL
函数原型如下 :
bool xxx_init(UDF_INIT *initid, UDF_ARGS *args, char *message);2.2.2.1.1.3 xxx_deinit()
xxx()的析构函数 , 用于释放初始化函数分配的内存或做其它清理工作 , 这个函数是可选的。 函数原型如下:
void xxx_deinit(UDF_INIT *initid);2.2.2.1.2 UDF 执行流程
当在一个SQL语句中调用XXX()时 , MySQL首先调用xxx_init()函数做必要的初始化工作 , 比如: 参数检查、内存分配等。 如果xxx_init() 返回错误 , 则主函数xxx()和析构函数xxx_deinit()不会被调用 , 整个语句会报错退出。如果xxx_init()执行成功MySQL会调用主函数xxx() ,通常情况下会每行数据调用一次 , 依赖于XXX()在SQL语句中的位置。当所有的主函数xxx()都调用完成后 , MySQL会调用对应的析构函数xxx_deinit()做必要的清理工作。
注意 , 以上所有的函数都要求是线程安全的。同时如果是用C++实现的 , 那么在定义的函数开头必须要加上extern "C" , 以便MySQL可以找到相应的符号。
2.2.2.1.3 UDF实现相关数据结构说明
UDF_INIT是参数
initid的类型 , 该参数是3个函数都需要的 , 可以在xxx_init函数中初始化。该结构的主要成员如下 :bool maybe_null: 如果xxx()可以返回NULL,xxx_init函数需要把它设置成true, 如果函数参数有maybe_null是true的 , 该值的默认值就是true。unsigned int max_length: 返回值的最大长度。对于不同返回类型该值的默认值不同 , 对于STRING, 默认值和和最长的函数参数相等。对于INTEGER, 默认值是21。如果是BLOB类型的 , 可以将它设置成65KB或16MB。char *ptr: 一个透明的指针 ,UDF的实现可以自己根据需要使用。该指针一般在xxx_init()里分配内存 , 在xxx_deinit()里进行释放。bool const_item: 如果xxx()函数总是返回相同的值 ,xxx_init()中可以把该值设置成true。
UDF_ARGS是参数
args是数据类型 , 主要成员如下:unsigned int arg_count:SQL函数参数的个数 , 也是下面其他成员的数组长度。可以在xxx_init()函数里检查是否与预期一致 , 如:if (args->arg_count != 2) { strcpy(message, "XXX() requires two arguments"); return 1; }enum Item_result *arg_type: 是一个定义了每个参数类型的数组 , 每个元素可能的取值 :TRING_RESULT,INT_RESULT,REAL_RESULT, 和DECIMAL_RESULT。 也可以通过它在xxx_init()里指定某个参数的数据类型 ,MySQL会将输入的参数强制转化为该类型。char **args: 对于xxx_init(), 当参数是常量时 , 比如3、4*7-2或SIN(3.14) args->args[i]指向参数值 , 当参数是非常量时args->args[i]为NULL; 对于主函数xxx()总是指向参数的值 , 如果参数i为null, 则args->args[i]为NULL。对于
STRING_RESULT类型 ,args->args[i]指向对应的字符串 ,args->lengths[i]是字符串长度。对于
INT_RESULT类型 , 需要强制转化成long long:long long int_val = *(long long *) args->args[i];对于
REAL_RESULT类型 , 需要转成double:double real_val = *(double *) args->args[i]unsigned long *lengths: 对于xxx_init()函数该数组包含每个参数的最大长度 , 对于xxx()函数为参数的实际长度。char *maybe_null: 对于xxx_init()该成员表示对应的参数是否可以为null。**attributes: 表示传入参数的参数名 , 参数名的长度在args->attribute_lengths[i]中。
2.2.2.1.4 UDF返回值及错误处理
如果有错误发生xxx_init()应该返回true , 同时将错误消息保存在message参数中 , message参数的buffer长度为 MYSQL_ERRMSG_SIZE(512) 。对于long long和double的SQL函数的返回值通过主函数xxx()的返回值返回。字符串类型的SQL函数 如果字符串长度小于255 ,可以通过参数result参数返回 , 实际长度存在*length中 , xxx()函数要返回result ;如果要返回的字符串长度大于255 , 需要自己分配内存并通过xxx()返回值返回。分配的内存需要在xxx_deinit里释放。可以通过设置*is_null = 1来表示SQL函数返回值为null。另外如果函数发生错误需要设置*error = 1。
2.2.2.1.5 UDF的编译和安装
这里只讲Linux下编译和安装 , 编译可以使用如下命令:
c++ -I$(MYSQL_INSTALLDIR)/include -fPIC -g -shared \
-o $(MYSQL_INSTALLDIR)/lib/plugin/libmyudf.so myudf.cc这里MYSQL_INSTALLDIR指的是MySQL的安装目录。编译完成后生成的目标动态库直接写到了MySQL的安装目录的plugin目录下 , mysqld只在这个目录上寻找UDF实现动态库。
2.2.2.2 UDF函数的使用
使用mysql命令连接到MySQL server , 执行以下查询在数据库中生成SQL函数
CREATE FUNCTION myudf RETURNS INT SONAME 'libmyudf.so';这里在的libmyudf.so是前面编译生成的动态库。可以通过系统表mysql.func和performance_schema下的user_defined_functions 来跟踪系统中已经安装的UDF。
9.2.2.3 一个简单的例子
#include "mysql.h"
#include <sys/types.h> /* getpid() */
#include <unistd.h> /* getpid() */
extern "C" bool
mysqld_pid_init(UDF_INIT *initid __attribute__((unused)),
UDF_ARGS *args __attribute__((unused)),
char *message __attribute__((unused)))
{
return false;
}
extern "C" long long
mysqld_pid(UDF_INIT *initid __attribute__((unused)),
UDF_ARGS *args __attribute__((unused)),
char *is_null __attribute__((unused)),
char *error __attribute__((unused)))
{
return getpid();
}这个例子实现了一个简单的UDF : mysqld_pid() , 该UDF可以拿到mysqld进程的PID , 可以通过SQL语句select mysqld_pid()调用。 将以上例子拷贝到一个文件 , 比如mysqld_pid.cc然后进行编译:
c++ -I$(MYSQL_INSTALLDIR)/include -fPIC -g -shared -o \
$(MYSQL_INSTALLDIR)/lib/plugin/libmysqld_pid.so mysqld_pid.cc最后通过mysql连接到数据库执行如下SQL语句 , 将mysqld_pid安装到数据库 , 用户就可以在SQL语句上使用了。
CREATE FUNCTION mysqld_pid RETURNS INT SONAME 'libmysqld_pid.so';
