
1. 关系型数据库常见组件
数据库 :
database表 :
table; 行 :row; 列 :cloumn索引 :
index视图 :
view用户 :
user权限 :
privilege存储过程 :
procedure存储函数 :
function触发器 :
trigger事件调度器 :
event scheduler, 任务计划
2. SQL 语言的兴起与语法标准
20世纪70年代 , IBM开发出SQL , 用于DB2 1981年 , IBM推出SQL/DS数据库 业内标准微软和Sybase的T-SQL , Oracle的PL/SQL SQL作为关系型数据库所使用的标准语言 , 最初是基于IBM的实现在1986年被批准的。1987年 , 国际标准化组织(ISO) 把ANSI(美国国家标准化组织)SQL作为国际标准 SQL : ANSI SQL , SQL-1986, SQL-1989, SQL-1992, SQL-1999, SQL-2003 , SQL-2008, SQL-2011
2.1 SQL 语言规范
在数据库系统中 , SQL语句不区分大小写 , 建议用大写 SQL语句可单行或多行书写 , 以;结尾 关键词不能跨多行或简写 用空格和缩进来提高语句的可读性 子句通常位于独立行 , 便于编辑 , 提高可读性。
注释 :
SQL标准:
--注释内容: 单行注释, 注意有空格/*注释内容*/: 多行注释MYSQL注释
# 注释内容
2.2 数据库对象和命名
数据库的组件(对象) : 数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
命名规则:
必须以字母开头 , 可包括数字和三个特殊字符(
#_$)不要使用
MySQL的保留字同一
database(Schema)下的对象不能同名
2.3 SQL 语句分类
DDL:
Data Defination Language数据定义语言CREATE,DROP,ALTERDML :
Data Manipulation Language数据操纵语言INSERT,DELETE,UPDATEDQL :
Data Query Language数据查询语言SELECTDCL :
Data Control Language数据控制语言GRANT,REVOKE,COMMIT,ROLLBACK
2.4 SQL 语句构成
关健字Keyword组成子句clause , 多条clause组成语句 示例 : 数据库操作
SELECT * #SELECT子句
FROM products #FROM子句
WHERE price>400 #WHERE子句获取SQL 命令使用帮助 : 官方帮助 : https://dev.mysql.com/doc/refman/8.0/en/sql-statements.html
mysql> HELP KEYWORD2.5 字符集排序
2.5.1 字符集变量
早期MySQL版本默认为latin1 , 从MySQL8.0开始默认字符集已经为utf8mb4。
查看支持所有字符集:
MariaDB [(none)]> SHOW CHARACTER SET ;编辑MySQL的配置文件 , 修改服务器默认字符集为utf8mb4。 只需要关心5个系统变量 , 这5个都改为utf8mb4则修改成功 : character_set_client character_set_connection character_set_results character_set_server character_set_database
查看当前字符集的使用情况:
MariaDB [(none)]> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)MySQL中字符集相关变量:character_set_client: 客户端请求数据的字符集character_set_connection: 从客户端接受到数据,然后传输的字符集character_set_database: 默认数据库的字符集,无论默认数据库如何改变,都是这个字符集;如果没有默认数据库 , 那就使用character_set_server指定的字符集 , 这个变量建议由系统自己管理 , 不要人为定义。character_set_filesystem: 把操作系统上的文件名转化成此字符集 , 即把character_set_client转换character_set_filesystem, 默认binary是不做任何转换的character_set_results: 结果集的字符集character_set_server: 数据库服务器的默认字符集character_set_system: 存储系统元数据的字符集 , 总是 utf8 , 不需要设置
设置服务器默认的字符集
vim /etc/my.cnf
[mysqld]
character-set-server=utf8mb4设置mysql客户端默认的字符集
vim /etc/my.cnf
[mysql]
default-character-set=utf8mb4示例 :
MariaDB [(none)]> SHOW CHARACTER SET ;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+----------+-----------------------------+---------------------+--------+
39 rows in set (0.00 sec)
[root@centos7 ~]# ll /usr/share/mysql/charsets/
total 232
-rw-r--r--. 1 root root 5526 May 6 2020 armscii8.xml
-rw-r--r--. 1 root root 5512 May 6 2020 ascii.xml
-rw-r--r--. 1 root root 8241 May 6 2020 cp1250.xml
-rw-r--r--. 1 root root 8365 May 6 2020 cp1251.xml
-rw-r--r--. 1 root root 5569 May 6 2020 cp1256.xml
-rw-r--r--. 1 root root 8902 May 6 2020 cp1257.xml
-rw-r--r--. 1 root root 5506 May 6 2020 cp850.xml
-rw-r--r--. 1 root root 5528 May 6 2020 cp852.xml
-rw-r--r--. 1 root root 5613 May 6 2020 cp866.xml
-rw-r--r--. 1 root root 6529 May 6 2020 dec8.xml
-rw-r--r--. 1 root root 5516 May 6 2020 geostd8.xml
-rw-r--r--. 1 root root 5728 May 6 2020 greek.xml
-rw-r--r--. 1 root root 5517 May 6 2020 hebrew.xml
-rw-r--r--. 1 root root 5502 May 6 2020 hp8.xml
-rw-r--r--. 1 root root 18307 May 6 2020 Index.xml
-rw-r--r--. 1 root root 5529 May 6 2020 keybcs2.xml
-rw-r--r--. 1 root root 5510 May 6 2020 koi8r.xml
-rw-r--r--. 1 root root 6532 May 6 2020 koi8u.xml
-rw-r--r--. 1 root root 9816 May 6 2020 latin1.xml
-rw-r--r--. 1 root root 7238 May 6 2020 latin2.xml
-rw-r--r--. 1 root root 5515 May 6 2020 latin5.xml
-rw-r--r--. 1 root root 7438 May 6 2020 latin7.xml
-rw-r--r--. 1 root root 8047 May 6 2020 macce.xml
-rw-r--r--. 1 root root 8058 May 6 2020 macroman.xml
-rw-r--r--. 1 root root 1749 May 6 2020 README
-rw-r--r--. 1 root root 6530 May 6 2020 swe7.xml
范例: 默认的字符集合排序规则
MariaDB [(none)]> SELECT VERSION();
+----------------+
| VERSION() |
+----------------+
| 5.5.68-MariaDB |
+----------------+
1 row in set (0.00 sec)
MariaDB [(none)]> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
MariaDB [(none)]> SHOW VARIABLES LIKE 'collation%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | utf8_general_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set (0.00 sec)2.5.2 排序字符集collation
MariaDB [(none)]> show variables like "%coll%";
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | utf8_general_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set (0.01 sec)字符除了需要存储 , 还需要排序或比较大小。推荐用utf8mb4_unicode_ci , 但是用utf8mb4_general_ci也没啥问题。
utf8_general_ci与utf8_unicode_ci区别utf8_unicode_ci和utf8_general_ci, 对中文、英文来说没有实质的差别 , 用utf8_general_ci就可以(因为:utf8_general_ci比对速度快)utf8_general_ci比对速度快 , 但准确度稍差。utf8_unicode_ci准确度高 , 但比对速度稍慢。如果你的应用有德语、法语或者俄语 , 请一定使用
utf8_unicode_ci。一般用utf8_general_ci就够了
MySQL 8.0默认的是utf8mb4_0900_ai_ci, 属于utf8mb4_unicode_ci中的一种 , 具体含义如下 :uft8mb4表示用UTF-8编码方案 , 每个字符最多占4个字节。0900指的是Unicode校对算法版本。(Unicode归类算法是用于比较符合Unicode标准要求的两个Unicode字符串的方法) 。ai指的是口音不敏感。也就是说 , 排序时e,è,é,ê和ë之间没有区别。as指对口音敏感。ci表示不区分大小写。也就是说 , 排序时p和P之间没有区别。cs标识区分大小写。ci是case insensitive的缩写 ,cs是case sensitive的缩写。即指定大小写是否敏感。如果需要口音敏感和区分大小写 , 则可以使用
utf8mb4_0900_as_cs代替。
utf8mb4已成为默认字符集 , 在MySQL 8.0.1及更高版本中将utf8mb4_0900_ai_ci作为默认排序规则。以前 ,utf8mb4_general_ci是默认排序规则。由于utf8mb4_0900_ai_ci排序规则现在是默认排序规则 , 因此默认情况下新表格可以存储基本多语言平面之外的字符。现在可以默认存储表情符号。
2.5.2.1 collate用途
所谓utf8_unicode_ci , 其实是用来排序的规则。对于mysql中那些字符类型的列 , 如VARCHAR , CHAR , TEXT类型的列 , 都需要有一个COLLATE类型来告知mysql如何对该列进行排序和比较。简而言之 , COLLATE会影响到ORDER BY语句的顺序 , 会影响到WHERE条件中大于小于号筛选出来的结果 , 会影响DISTINCT、GROUP BY、HAVING语句的查询结果。另外 , mysql建索引的时候 , 如果索引列是字符类型 , 也会影响索引创建 ,只不过这种影响我们感知不到。总之 , 凡是涉及到字符类型比较或排序的地方 , 都会和COLLATE有关。
2.5.2.2 各种collate的区别
COLLATE通常是和数据编码(CHARSET)相关的 , 一般来说每种CHARSET都有多种它所支持的COLLATE , 并且每种CHARSET都指定一种COLLATE为默认值。例如Latin1编码的默认COLLATE为latin1_swedish_ci , GBK编码的默认COLLATE为gbk_chinese_ci , utf8mb4编码的默认值为utf8mb4_general_ci。
这里顺便讲个题外话 , mysql中有utf8和utf8mb4两种编码 , 在mysql中请大家忘记utf8 , 永远使用utf8mb4 。这是mysql的一个遗留问题 , mysql中的utf8最多只能支持3bytes长度的字符编码 , 对于一些需要占据4bytes的文字 , mysql的utf8就不支持了 , 要使用utf8mb4才行。
很多COLLATE都带有_ci字样 , 这是Case Insensitive的缩写 , 即大小写无关 , 也就是说"A"和"a"在排序和比较的时候是一视同仁的。selection * from table1 where field1="a"同样可以把field1为"A"的值选出来 。与此同时 , 对于那些_cs后缀的COLLATE , 则是Case Sensitive , 即大小写敏感的。
在mysql中使用show collation指令可以查看到mysql所支持的所有COLLATE。以utf8mb4为例 , 该编码所支持的所有COLLATE如下图所示。
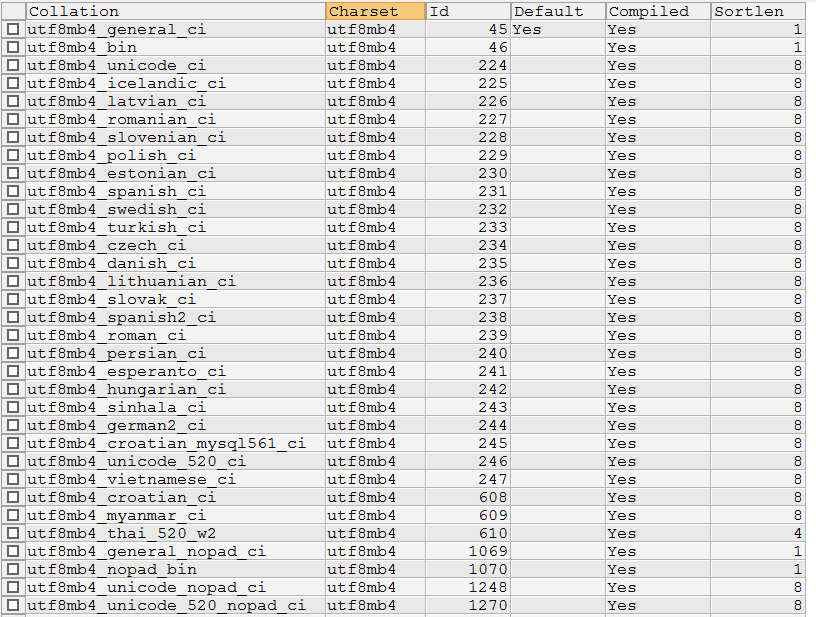
图中我们能看到很多国家的语言自己的排序规则。在国内比较常用的是utf8mb4_general_ci(默认)、utf8mb4_unicode_ci 、utf8mb4_bin这三个。我们来探究一下这三个的区别 :
首先utf8mb4_bin的比较方法其实就是直接将所有字符看作二进制串 , 然后从最高位往最低位比对。所以很显然它是区分大小写的。
而utf8mb4_unicode_ci和utf8mb4_general_ci对于中文和英文来说 , 其实是没有任何区别的。对于我们开发的国内使用的系统来说 , 随便选哪个都行。只是对于某些西方国家的字母来说 , utf8mb4_unicode_ci会比utf8mb4_general_ci 更符合他们的语言习惯一些 , general是mysql一个比较老的标准了。例如 , 德语字母“ß” , 在utf8mb4_unicode_ci中是等价于"ss"两个字母的(这是符合德国人习惯的做法) , 而在utf8mb4_general_ci 中 , 它却和字母“s”等价。不过 , 这两种编码的那些微小的区别 , 对于正常的开发来说 , 很难感知到。本身我们也很少直接用文字字段去排序 , 退一步说 , 即使这个字母排错了一两个 , 真的能给系统带来灾难性后果么?从网上找的各种帖子讨论来说 , 更多人推荐使用utf8mb4_unicode_ci , 但是对于使用了默认值的系统 , 也并没有非常排斥, 并不认为有什么大问题。结论 : 推荐使用utf8mb4_unicode_ci , 对于已经用了utf8mb4_general_ci 的系统 , 也没有必要花时间改造。
另外需要注意的一点是 , 从mysql 8.0开始 , mysql默认的CHARSET已经不再是Latin1了 , 改为了utf8mb4 , 并且默认的COLLATE也改为了utf8mb4_0900_ai_ci。utf8mb4_0900_ai_ci大体上就是unicode的进一步细分 , 0900指代unicode比较算法的编号(Unicode Collation Algorithm version) , ai表示accent insensitive( 发音无关) , 例如e,è,é,ê 和ë是一视同仁的。
2.5.2.3 COLLATE设置级别及其优先级
设置COLLATE可以在实例级别、库级别、表级别、列级别、以及SQL指定。实例级别的COLLATE设置就是mysql配置文件或启动指令中的collation_connection系统变量。
库级别设置COLLATE的语句如下:
CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;如果库级别没有设置CHARSET和COLLATE , 则库级别默认的CHARSET和COLLATE使用实例级别的设置。在mysql8.0 以下版本中 , 你如果什么都不修改 , 默认的CHARSET是Latin1 , 默认的COLLATE是latin1_swedish_ci 。从mysql8.0开始 , 默认的CHARSET已经改为了utf8mb4 , 默认的COLLATE改为了utf8mb4_0900_ai_ci。
表级别的COLLATE设置 , 则是在CREATE TABLE的时候加上相关设置语句 , 例如 :
CREATE TABLE ( ……` ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;如果表级别没有设置CHARSET和COLLATE , 则表级别会继承库级别的CHARSET与COLLATE。
列级别的设置 , 则在CREATE TABLE中声明列的时候指定 , 例如
CREATE TABLE ( field1 VARCHAR (64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' , …… )……如果列级别没有设置CHARSET和COLATE , 则列级别会继承表级别的CHARSET与COLLATE。
最后 , 你也可以在写SQL查询的时候显示声明COLLATE来覆盖任何库表列的COLLATE设置 , 不太常用 , 了解即可 :
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1;
SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;如果全都显示设置了 , 那么优先级顺序是SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置。也就是说列上所指定的COLLATE可以覆盖表上指定的COLLATE , 表上指定的COLLATE可以覆盖库级别的COLLATE 。如果没有指定 , 则继承下一级的设置。即列上面没有指定COLLATE , 则该列的COLLATE和表上设置的一样。
以上就是关于mysql的COLLATE相关知识。不过 , 在系统设计中,我们还是要尽量避免让系统严重依赖中文字段的排序结果 , 在mysql的查询中也应该尽量避免使用中文做查询条件。

