
1. 分库分表介绍
随着互联网以及移动互联网的发展 , 应用系统的数据量也是成指数式增长 , 若采用单数据库进行数据存储 , 存在以下性能瓶颈:
IO瓶颈: 热点数据太多 , 数据库缓存不足 , 产生大量磁盘IO, 效率太低。请求数据太多 , 带宽不够 , 网络IO瓶颈。CPU瓶颈: 排序 , 分组 , 连接查询 , 聚合统计等SQL会耗费大量的CPU资源 , 请求数太多 ,CPU出现瓶颈。
未来解决上述问题 , 我们需要对数据库进行分库分表处理
分库分表的中心思想都是将数据分散存储 , 使得单一数据库/表的数据量变小来缓解单一数据库的性能问题 , 从而达到提升数据库性能的目的。
2. 拆分策略
分库分表的形式 , 主要是两种: 垂直拆分和水平拆分。而拆分的粒度 , 一般又分为分库和分表 , 所以组成的拆分策略最终如下:
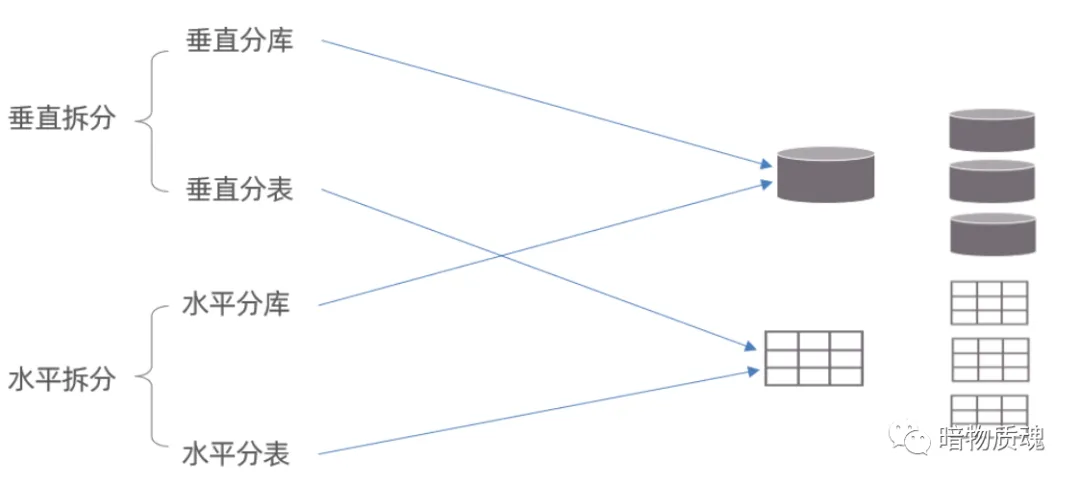
2.1 垂直拆分
垂直分库
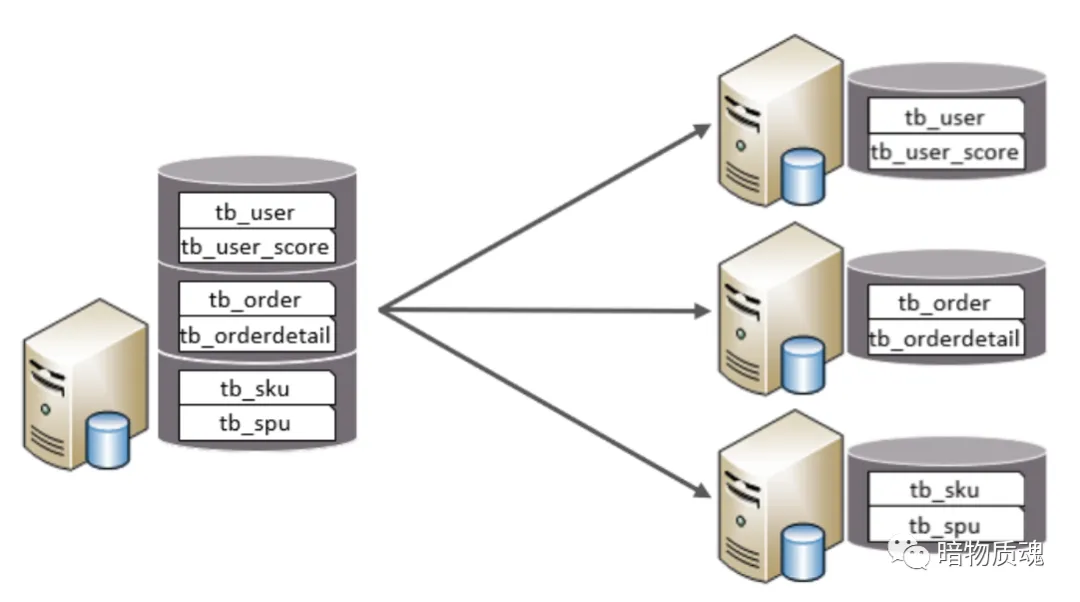
以表为依据 , 根据业务将不同表拆分到不同库中。
特点:
每个库的表结构都不一样
每个库的数据也不一样
所有库的并集是全量数据
垂直分表
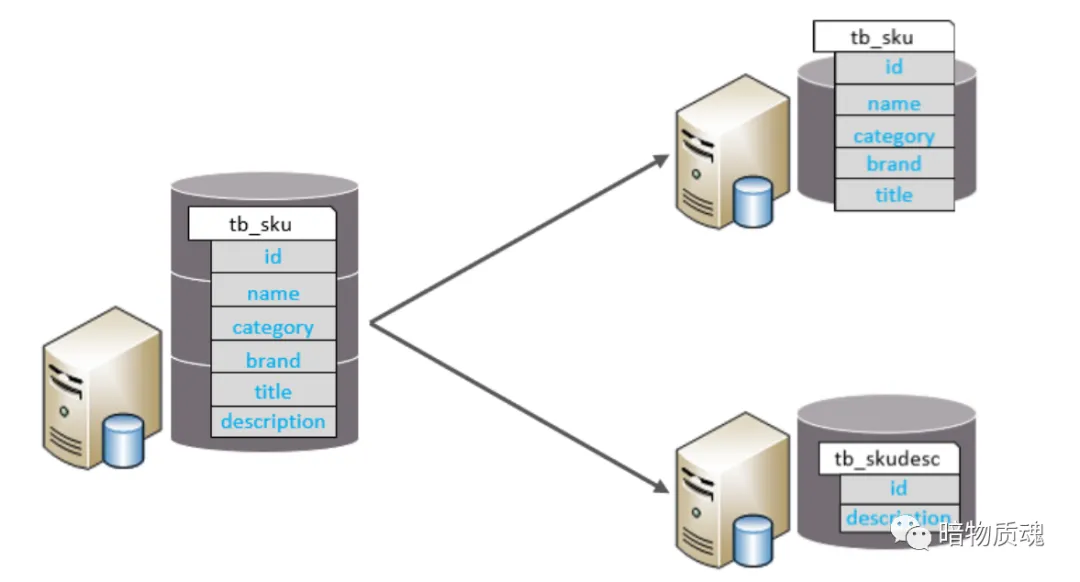
以字段为依据 , 根据字段属性将不同字段拆分到不同表中
特点
每个表的结构都不一样
每个表的数据也不一样 , 一般通过一列(主键/外键)关联
所有表的并集是全量数据
2.2 水平拆分
水平分库
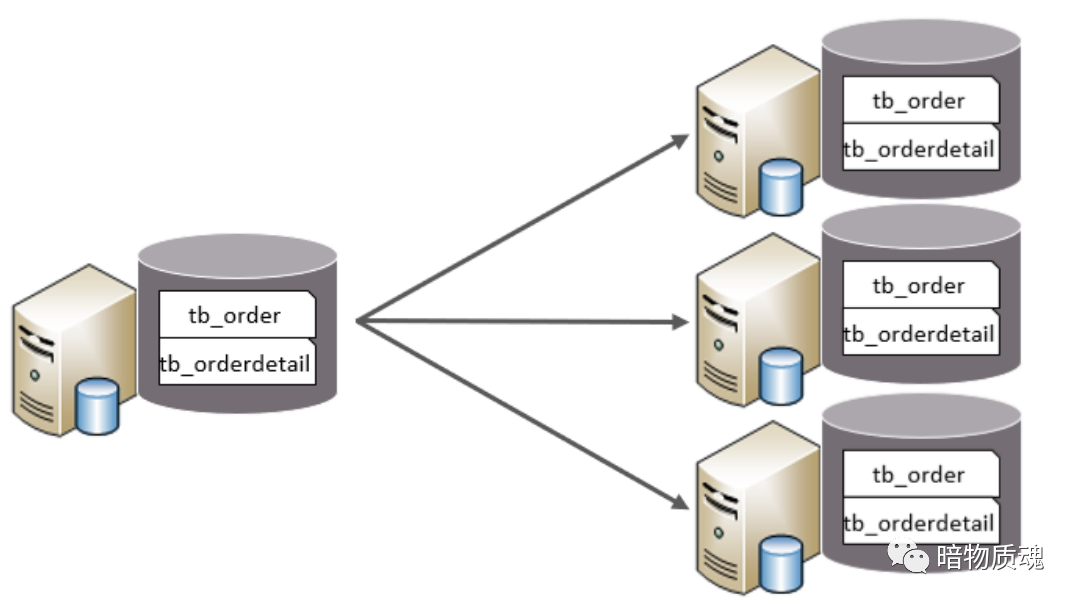
以字段为依据 , 按照一定策略 , 将一个库的数据拆分到多个库中
特点
每个库的表结构都一样
每个库的数据都不一样
所有库的并集是全量数据
水平分表
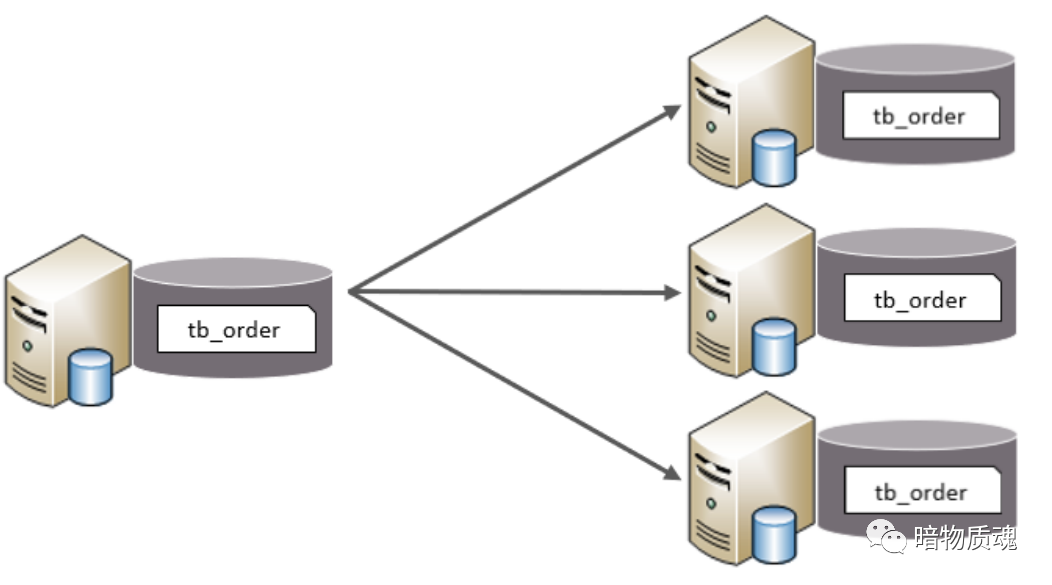
以字段为依据 , 按照一定策略 , 将一个表的数据拆分到多个表中
特点
每个表的表结构都一样
每个表的数据都不一样
所有表的并集是全量数据
在业务系统中 , 未来缓解磁盘IO以及CPU的性能瓶颈 , 到底是垂直拆分还是水平拆分;具体看分库还是分表 , 都需要根据具体业务需求具体分析。
3. MyCat 基础
3.1 MyCat 介绍
MyCat是开源的 , 活跃的 , 基于Java语言编写的MySQL数据库中间件。可以像使用MySQL一样来使用MyCat , 对于开发人员来说根本感觉不到MyCat的存在。
开发人员只需要连接MyCat即可 , 而具体底层用到几台数据库 , 每一台数据库服务器里面存储了什么数据 , 都无需关心。而具体的分库分表的策略 , 只需要在MyCat中配置即可。
除了MyCat之外还有shardingJDBC等技术区实现分库分表。
官网地址: http://www.mycat.org.cn/
mycat2 页面: MyCat2
MyCat最早的版本完成与2013年年底。最早是叫做OpencloudDB , 后来改成MyCat。这其中有一个重要的原因 , 就是打算入驻Apache , 与Tomcat异曲同工。MyCat的前身阿里内部的Cobar框架。Cobar是阿里研发的关系型数据库分布式处理系统 , 最重要的特性就是分库分表。而MyCat则是对Cobar的一些问题进行改良 , 并开源出来的。
MyCat从诞生之初就带上了程序员桀骜不驯的标签 , 不依托于任何商业公司 , 以社区的形式进行维护。曾经的MyCat社区 , 聚集了国内大部分的IT经营 , 一度是中国最大的IT社区。MyCat产品也是在迅猛发展。从GitHub上使用者公布的案例中看到 , 在某些数量很大的系统中 , MyCat能支持处理单表单月30亿级别的数据量。
但是 , 社区化运营毕竟给产品开发带来了不稳定性。MyCat社区一度想要开发一个叫做MycloudOA的云平台产品。但是 , 目标过大的结果是团队凝聚力逐渐下降。MyCat的产品版本发展到1.6就沉寂了很长一段时间。
而现在MyCat2产品相当于是重新收拾之前MyCat留下的烂摊子 , 重整山河 , 再次出发。以下是官方公布的MyCat1.6和MyCat2的功能比较。
3.2 MyCat2 原理
MyCat的工作原理其实并不复杂。就是对请求进行“拦截”。他会拦截客户端发送过来的SQL语句 , 对SQL语句做一些特定的分析 , 如分片分析、路由分析、读写分离分析、缓存分析等。然后将此SQL发往后端的真实数据库。并将返回的结果做适当的处理 , 比如结果聚合、排序等 , 最终返回给用户。
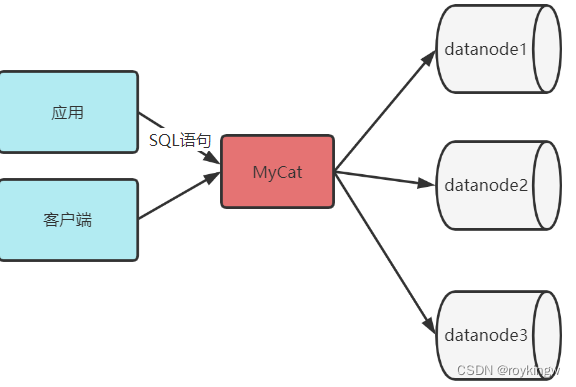
而在工作方式上 , MyCat会部署成一个MySQL服务 , 程序员只需要像操作普通的单机MySQL服务一样去操作MyCat。MyCat再去完成分库分表功能。而后端的数据库产品 , 建议还是使用MySQL。当然 , MyCat2目前也在开始提交与更多数据库产品的兼容。目前提交了Oracle的兼容版本 , 但是还没有到发布版本。
3.3 MyCat 入门
MyCat2是基于Java开发的 , 所以他的运行环境是比较简单的 , 只需要安装JDK即可。接下来准备一台Linux机器 , 搭建JDK8版本。初始搭建时 , 建议在这台服务器上也搭建一个MySQL服务。这里由于MyCat官网给定的下载网址一直无法打开 , 这里直接通过github下载源码编译的方式安装的。
这里需要注意MyCat2的安装包分为基础包和环境运行的Jar包。这里通过github编译安装的是jar包。基础包从网上其他地方找到的。
基础包下载地址:https://download.csdn.net/download/qq_42335715/89469711
具体步骤如下:
通过
github下载源码包
下载依赖包
dnf install unzip maven git java-1.8.0-openjdk解压软件包 , 并切换到对应目录中
unzip Mycat2-v1.22-2022-6-25.zip -d /opt/ cd /opt/Mycat2-v1.22-2022-6-25/开始编译安装
mvn clean install编译完成之后 , 会生成需要的
jar包[root@23 Mycat2-v1.22-2022-6-25]# ll mycat2/target/mycat2-1.22-release-jar-with-dependencies.jar -rw-r--r-- 1 root root 152877591 Apr 9 03:30 mycat2/target/mycat2-1.22-release-jar-with-dependencies.jar直接通过
CSDN下载mycat2的基础包解压基础包
[root@23 ~]# unzip mycat2.zip -d /opt/ [root@23 ~]# ll /opt/ total 8 drwxr-xr-x 5 root root 4096 Apr 9 22:52 mycat2 drwxr-xr-x 29 root root 4096 Apr 9 03:25 Mycat2-v1.22-2022-6-25修改基础包中的文件权限
[root@23 ~]# chmod +x /opt/mycat2/bin/* [root@23 ~]# ll /opt/mycat2/bin/* -rwxr-xr-x 1 root root 15666 Jun 22 2024 /opt/mycat2/bin/mycat -rwxr-xr-x 1 root root 3916 Jun 22 2024 /opt/mycat2/bin/mycat.bat -rwxr-xr-x 1 root root 281540 Jun 22 2024 /opt/mycat2/bin/wrapper-aix-ppc-32 -rwxr-xr-x 1 root root 319397 Jun 22 2024 /opt/mycat2/bin/wrapper-aix-ppc-64 -rwxr-xr-x 1 root root 253808 Jun 22 2024 /opt/mycat2/bin/wrapper-hpux-parisc-64 -rwxr-xr-x 1 root root 140198 Jun 22 2024 /opt/mycat2/bin/wrapper-linux-ppc-64 -rwxr-xr-x 1 root root 99401 Jun 22 2024 /opt/mycat2/bin/wrapper-linux-x86-32 -rwxr-xr-x 1 root root 111027 Jun 22 2024 /opt/mycat2/bin/wrapper-linux-x86-64 -rwxr-xr-x 1 root root 114052 Jun 22 2024 /opt/mycat2/bin/wrapper-macosx-ppc-32 -rwxr-xr-x 1 root root 233604 Jun 22 2024 /opt/mycat2/bin/wrapper-macosx-universal-32 -rwxr-xr-x 1 root root 253432 Jun 22 2024 /opt/mycat2/bin/wrapper-macosx-universal-64 -rwxr-xr-x 1 root root 112536 Jun 22 2024 /opt/mycat2/bin/wrapper-solaris-sparc-32 -rwxr-xr-x 1 root root 148512 Jun 22 2024 /opt/mycat2/bin/wrapper-solaris-sparc-64 -rwxr-xr-x 1 root root 110992 Jun 22 2024 /opt/mycat2/bin/wrapper-solaris-x86-32 -rwxr-xr-x 1 root root 204800 Jun 22 2024 /opt/mycat2/bin/wrapper-windows-x86-32.exe -rwxr-xr-x 1 root root 220672 Jun 22 2024 /opt/mycat2/bin/wrapper-windows-x86-64.exe 把依赖的
jar复制到安排目录的lib下[root@23 ~]# cp /opt/Mycat2-v1.22-2022-6-25/mycat2/target/mycat2-1.22-release-jar-with-dependencies.jar /opt/mycat2/lib/启动一个
MySQL服务,这里已经提前准备好了一个主从集群的MariadbMyCat在启动时需要先默认指定一个数据库 , 这里就默认MySQL数据库的配置信息【端口:3306, 用户名:root, 密码:123456】 , 然后创建一个名为mycat的数据库。配置
MyCat的数据源[root@23 ~]# cat /opt/mycat2/conf/datasources/prototypeDs.datasource.json { "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"prototypeDs", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://192.168.71.7:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8", "user":"root", "weight":0 } 启动
mycat[root@23 ~]# /opt/mycat2/bin/mycat start Starting mycat2... [root@23 ~]# /opt/mycat2/bin/mycat status mycat2 is running (17026). 其他额外命令
./mycat stop 停止 ./mycat console 前台运行 ./mycat install 添加到系统自动启动 ./mycat remove 取消随系统自动启动 ./mycat restart 重启 ./mycat pause 暂停 ./mycat status 查看启动状态之后尝试连接8066端口
[root@23 ~]# mysql -uroot -p123456 -h127.0.0.1 -P8066 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 0 Server version: 5.7.33-mycat-2.0 MariaDB Server Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> show databases; +--------------------+ | `Database` | +--------------------+ | information_schema | | mysql | | performance_schema | +--------------------+ 3 rows in set (0.157 sec) MySQL [(none)]> create database t1; Query OK, 0 rows affected (0.357 sec) MySQL [(none)]> show databases; +--------------------+ | `Database` | +--------------------+ | information_schema | | mysql | | performance_schema | | t1 | +--------------------+ 4 rows in set (0.041 sec)
4. MyCat 配置文件
4.1 用户信息(users)
文件位置: mycat/conf/users/{用户名}.user.json。
作用: 此文件主要配置MyCat的登录用户 , 也就是连接到8066这个端口的用户信息。
打开root.user.json , 看到配置内容如下
[root@23 ~]# cat /opt/mycat2/conf/users/root.user.json
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}
说明如下
dialect: 数据库(方言)类型 , 默认是mysqlip: 配置白名单使用 , 默认null。如果要限制ip访问 , 则需要配置需要访问的ippassword: 配置MyCAT用户的密码(明文)transactionType: 事务类型默认值:
proxy(本地事务 ,MyCat不做事务控制 , 具体的事务控制由后端的真实数据库控制 , 而且对于分布式场景下事务可能会失败 , 但是兼容性最好)可选值:
xa(分布式事务 , 需要确认存储节点集群类型是否支持XA)
username: 配置MyCAT用户的用户名
4.2 数据源(datasource)
文件位置: mycat/conf/datasources/{数据源名称}.datasource.json。
作用 : 配置MyCat连接真实数据库的数据源。
具体的配置如下:
[root@23 ~]# cat /opt/mycat2/conf/datasources/prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.71.7:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}
主要配置字段如下:
dbType: 数据源类型name: 数据源名字password: 真实MySQL的密码url: 真实MySQL的JDBC连接地址user: 真实MySQL的用户名weight: 配置数据源负载均衡的使用权重
4.3 逻辑库与逻辑表(logicaltable)
文件位置: mycat/conf/schemas/{库名}.schema.json
作用: 配置MyCat里面和MySQL对应的逻辑表。
打开root.user.json , 其主要配置字段如下
[root@23 ~]# cat /opt/mycat2/conf/schemas/t1.schema.json
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"t1",
"shardingTables":{},
"views":{}
}[root@23 ~]#
说明如下
customTables: 自定义表globalTables: 全局表normalTables: 默认表schemaName: 库名shardingTables: 分片表targetName: 数据源名 , 也可以是集群名
4.4 序列号(sequence)
文件位置: mycat/conf/sequences/{数据库名字}_{表名字}.sequence.json。 作用 : 使用序列号的分片表 , 对应的自增主键要在建表SQL中体现。
4.5 服务器(server)
文件位置 : mycat/server.json
作用 : MyCat的服务器的配置信息 , 一般无需额外配置。端口就在这里配置的。
{
"loadBalance": {
"defaultLoadBalance": "BalanceRandom",
"loadBalances": []
},
"mode": "local",
"properties": {},
"server": {
"bufferPool": {},
"idleTimer": {
"initialDelay": 3,
"period": 60000,
"timeUnit": "SECONDS"
},
"ip": "0.0.0.0",
"mycatId": 1,
"port": 8066,
"reactorNumber": 8,
"tempDirectory": null,
"timeWorkerPool": {
"corePoolSize": 0,
"keepAliveTime": 1,
"maxPendingLimit": 65535,
"maxPoolSize": 2,
"taskTimeout": 5,
"timeUnit": "MINUTES"
},
"workerPool": {
"corePoolSize": 1,
"keepAliveTime": 1,
"maxPendingLimit": 65535,
"maxPoolSize": 1024,
"taskTimeout": 5,
"timeUnit": "MINUTES"
}
}
}
4.6 集群clusters
目录: mycat/conf/clusters
命名规则:{集群名字}.cluster.json
主要配置内容:
[root@23 ~]# cat /opt/mycat2/conf/clusters/prototype.cluster.json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"prototypeDs"
],
"maxCon":200,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"switchType":"SWITCH"
}[root@23 ~]#
主要字段含义:
clusterType: 集群类型SIGNLE_NODE: 单一节点MASTER_SLAVE:普通主从另外针对高可用集群可支持
MHA和MGR
readBalanceType: 查询负载均衡策略,可选值BALANCE_ALL(默认值): 获取集群中所有数据源BALANCE_ALL_READ:获取集群中允许读的数据源BALANCE_READ_WRITE:获取集群中允许读写的数据源, 但允许读的数据源优先BALANCE_NODE: 获取集群中允许写数据源, 即主节点中选择
switchType: 切换类型NOT_SWITCH: 不进行主从切换SWITCH: 进行主从切换
masters: 主从集群中的主库名字。从库用replicas配置
5. 注释配置
MyCat需要通过注释的方式进行配置 , 其语法就是如此 , 可能是为了和数据库的执行语句做区分吧。
5.1 配置用户
创建用户
/*+ mycat:createUser{ "username":"admin", "password":"admin", "transactionType":"xa" } */删除用户
/*+ mycat:dropUser{ "username":"admin"} */显示用户
/*+ mycat:showUsers */
4.2 配置数据源
创建数据源
只需要设置
name、password、type、url、user几个字段即可/*+ mycat:createDataSource{ "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"数据源名称", "password":"数据库密码", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3306/数据库名?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"数据库用户名", "weight":0 } */;删除数据源
/*+ mycat:dropDataSource{ "name":"数据源名称" } */;显示数据源
/*+ mycat:showDataSources{} */
5.3 配置集群
创建集群
/*! mycat:createCluster{ "clusterType":"MASTER_SLAVE", "heartbeat":{ "heartbeatTimeout":1000, "maxRetry":3, "minSwitchTimeInterval":300, "slaveThreshold":0 }, "masters":[ "dc1" //主节点数据源名称 ], "maxCon":2000, "name":"c0", "readBalanceType":"BALANCE_ALL", "replicas":[ "dc2" //从节点数据源名称 ], "switchType":"SWITCH" } */;删除集群
/*! mycat:dropCluster{ "name":"c0" } */;显示集群
/*+ mycat:showClusters{} */
5.4 重置配置
把配置的信息重置为默认值
/*+ mycat:resetConfig{} */6. MyCat2 配置读写分离
为主节点
M1创建数据源由于其他参数都是默认的 , 无需修改 , 这里直接省略 , 只写主要的参数
/*+ mycat:createDataSource{ "dbType":"mysql", "name":"m1", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3307/test_demo?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root" } */;从节点M1S1创建数据源
/*+ mycat:createDataSource{ "dbType":"mysql", "name":"m1s1", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3308/test_demo?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root" } */;同时在文件夹中也生成了对应的配置文件
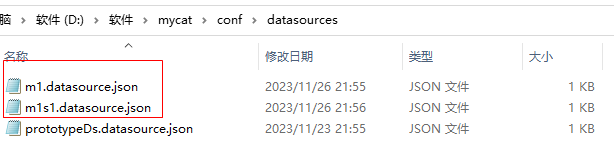
为主从节点搭建
MyCat集群 , 在MyCat将主从节点关联起来/*! mycat:createCluster{ "masters":[ "m1" ], "name":"zxh_test", "replicas":[ "m1s1" ] } */;指定了主节点和从节点 , 集群名称是
zxh_test, 查询结果可以看出 , 写操作只在
m1中允许 , 读操作可以在m1和m1s1之间轮询。创建逻辑库 , 用于指向集群
虽然上面已经配置好了集群 , 但如何去操作这个集群呢?这时可以创建一个数据库 , 这个库是逻辑库 , 关联到集群 , 那么后续只需要对这个逻辑库操作 , 就会转发到集群 , 集群再转发到主节点和从节点的逻辑数据源 , 这些逻辑数据源再分发到真实的数据库。这就是
MyCat2的读写分离。CREATE DATABASE test_demo DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;创建数据库(建议和真实数据库的库名一致)
指定逻辑库的集群名称
MyCat2暂时还未提供命令方式关联集群名称 , 这就需要手动打开配置文件conf/schemas/test_demo.schema.json, 在里面添加"targetName":"zxh_test",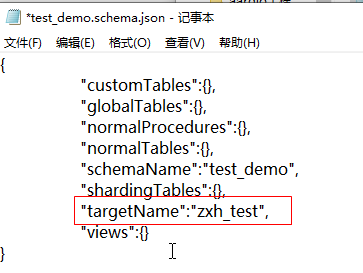
让逻辑库和集群进行对应 , 保存后重启
MyCat2服务。创建表进行测试
在
MyCat中创建表并添加数据进行测试use test_demo; CREATE TABLE `sys_enterprise` ( `id` int NOT NULL, `name` varchar(100) DEFAULT NULL, `ent_no` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; insert into sys_enterprise values(1,"武汉小米","A001"); insert into sys_enterprise values(2,"深圳腾讯小米","C001"); select * from sys_enterprise;在真实的数据库中查询
手动修改从节点真实库的数据(现实场景一般不允许直接修改从库数据) , 在
MyCat2中查询 , 发现查询的数据会出现不一样的情况 , 这更好的体现了读操作是在主节点和从节点之间轮询。从这里可以看出 , 并未对真实数据库操作 , 仅仅只是在MyCat进行操作 , 执行的SQL已按预期进行了读写操作 , 实现了读写分离。
7. 分库分表
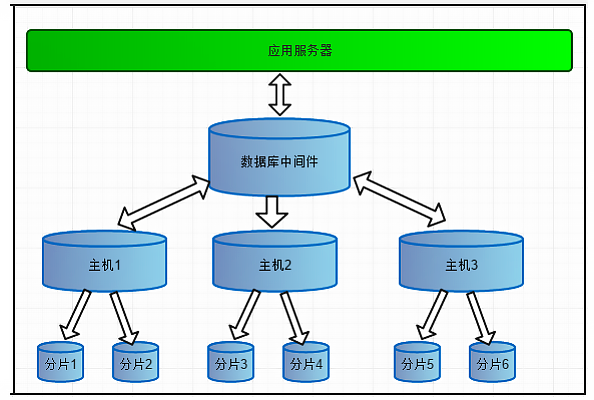
一个数据库由很多表构成 , 每个表对应着不同的业务 , 垂直切分是指按照业务不同将表进行分类 , 分散到不同的数据库上面 , 这样也就将数据或者说压力分担到不同的数据库上面 , 如下图 :
7.1 如何分库
分库原则 : 有紧密关联关系的表应该在一个库里 , 没有关联关系的表可以分到不同的库里。
# 客户表rows : 20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
# 订单表rows : 600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
# 订单详细表rows : 600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
# 订单状态字典表rows : 20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);以上四个表如何分库?客户表分在一个数据库 , 另外三张都需要关联查询 , 分在另外一个数据库。
7.2 如何分表
选择要拆分的表
MySQL单表存储数据条数是有瓶颈的 , 单表达到1000万条数据就达到了瓶颈 , 会影响查询效率 , 需要进行水平拆分(分表)进行优化。例如 : 例子中的
orders、orders\_detail都已经达到600万行数据 , 需要进行分表优化。分表字段
以
orders表为例 , 可以根据不同字段进行分表。
7.3 实现分库分表
Mycat2 的一大优势就是可以在终端直接创建数据源、集群、库表 , 并在创建时指定分库、分表。与 1.6 版本比大大简化了分库分表的操作。
7.3.1 配置数据源
很多网上的资料都没有加 url 参数 , 我实验时经常遇到各种参数问题 , 所以我在做实验的时候 , 加上了这些参数 , 避免报错 :
# 第一个写库
/*+ mycat:createDataSource{"name":"dw0","url":"jdbc:mysql://192.168.95.101:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第一个读库
/*+ mycat:createDataSource{"name":"dr0","url":"jdbc:mysql://192.168.95.201:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第二个写库
/*+ mycat:createDataSource{"name":"dw1","url":"jdbc:mysql://192.168.95.102:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;
# 第二个读库
/*+ mycat:createDataSource{"name":"dr1","url":"jdbc:mysql://192.168.95.202:3306/mysql?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true","user":"root","password":"WelC0me168!"} */;生成下面 4 个数据源文件 :
[root@guest mycat]# ll conf/datasources/d*
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dr0.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dr1.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:08 conf/datasources/dw0.datasource.json
-rw-r--r-- 1 root root 519 Dec 31 04:09 conf/datasources/dw1.datasource.json7.3.2、配置集群
# 在mycat2终端输入
# 配置第一组集群
/*! mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]}*/;
# 配置第二组集群
/*! mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]}*/;生成下面 2 个集群文件 :
[root@guest mycat]# ll conf/clusters/c*
-rw-r--r-- 1 root root 312 Dec 31 04:23 conf/clusters/c0.cluster.json
-rw-r--r-- 1 root root 312 Dec 31 04:23 conf/clusters/c1.cluster.json这里集群名 c0 , c1 是 MyCat2 默认支持的分片集群名字。不建议修改集群名字。按照使用习惯 , 接下来要配置逻辑库 , 然后逻辑库文件 xxx.schema.json 中指定目标集群。但是 mycat2 为了简化配置 , 在实现分库分表时 , 直接创建逻辑库和表的时候 , 指定规则 , 最终逻辑库文件会自动找到 c0、c1、...... 集群进行配置。
7.3.3 配置全局表
全局表表示在所有数据分片上都相同的表。比如字典表。
# 添加数据库db1
CREATE DATABASE db1;
# 在建表语句中加上关键字 BROADCAST(广播 , 即为全局表)
CREATE TABLE db1.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;配置完成后的全局表会写入到 mycat/conf/schemas/db1.schema.json 文件中。这样下次启动服务时就能够初始化表结构。
[root@guest mycat]# cat conf/schemas/db1.schema.json
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{},
"views":{}
}然后可以插入几条数据进行测试 :
INSERT INTO db1.`travelrecord` VALUES (1, "202212310001", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (2, "202212310002", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (3, "202212310003", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (4, "202212310004", CURDATE(),10,10,'ABC');
INSERT INTO db1.`travelrecord` VALUES (5, "202212310005", CURDATE(),10,10,'ABC');
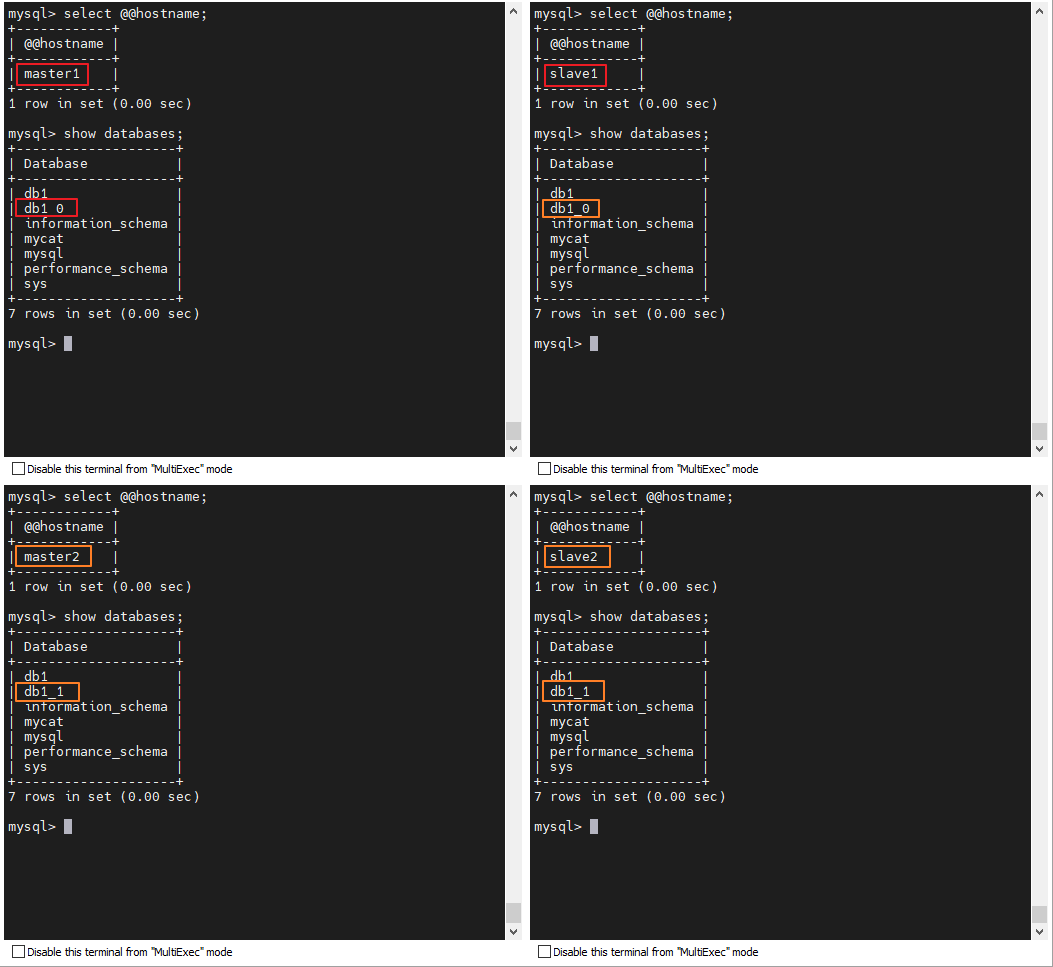
INSERT INTO db1.`travelrecord` VALUES (6, "202212310006", CURDATE(),10,10,'ABC');经测试 , 2 套一主一从集群中 , 每个 mysql 服务都有 db1.travelrecord 表 , 并且有完整的 6 条测试数据。
7.3.4、创建分片表(分库分表)
分片表表示逻辑表中的数据会分散保存到多个数据分片中。
# 在 Mycat 终端直接运行建表语句进行数据分片。
# 数据库分片规则 , 表分片规则 , 以及各分多少片。
# 核心就是后面的分片规则。 dbpartition表示分库规则 , tbpartition表示分表规则。而mod_hash表示按照customer_id字段取模进行分片。
# 意思是切2份到两个数据库集群 , 每个数据库集群切1份表(当然也可以切成多张表)
CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
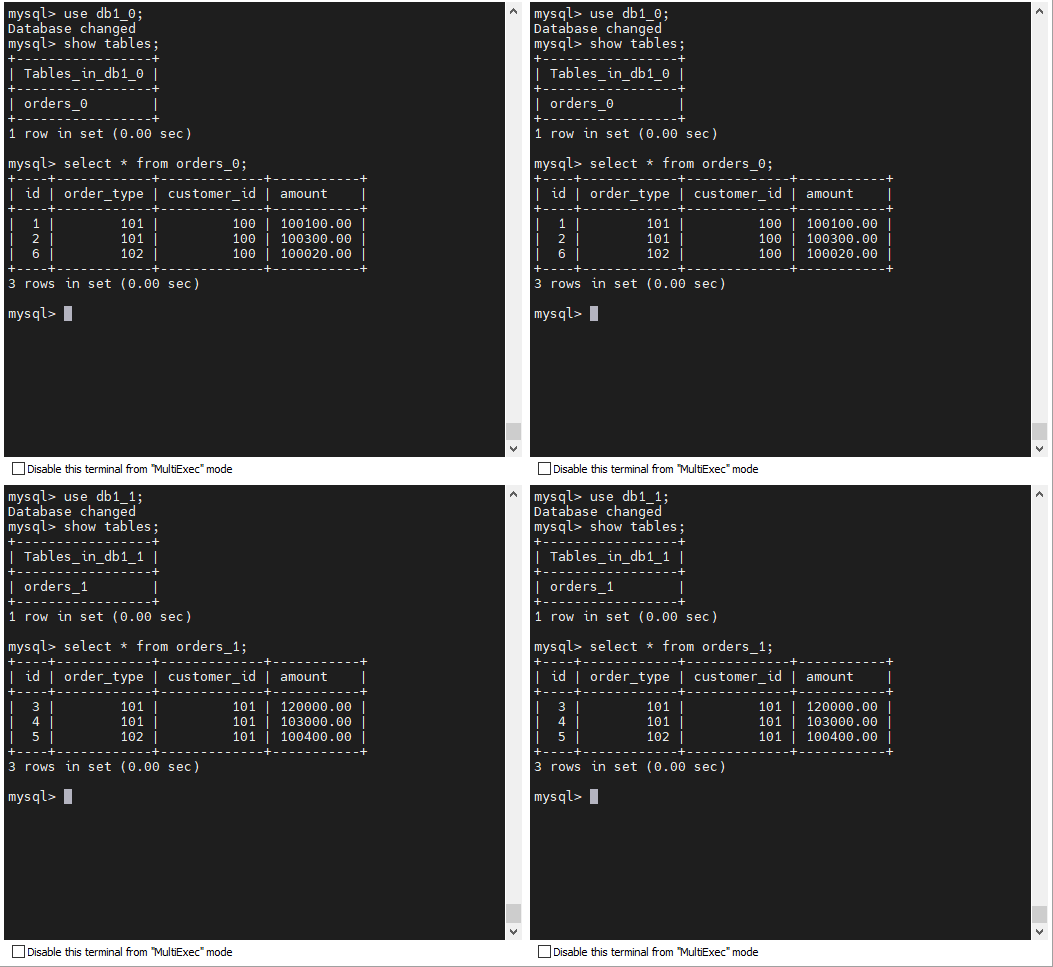
)ENGINE=INNODB DEFAULT CHARSET=utf8 dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 1 dbpartitions 2;接下来可以往测试表中插入部分测试数据进行验证。
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (6,102,100,100020);
mysql> SELECT * FROM orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 1 | 101 | 100 | 100100.00 |
| 2 | 101 | 100 | 100300.00 |
| 6 | 102 | 100 | 100020.00 |
| 3 | 101 | 101 | 120000.00 |
| 4 | 101 | 101 | 103000.00 |
| 5 | 102 | 101 | 100400.00 |
+----+------------+-------------+-----------+
6 rows in set (0.09 sec)此时 , 可以看一下自动生成的 schema 信息 :
[root@guest mycat]# cat conf/schemas/db1.schema.json
{
"customTables":{},
"globalTables":{
"travelrecord":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE db1.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{
"orders":{
"createTableSQL":"CREATE TABLE db1.orders (\n\tid BIGINT NOT NULL AUTO_INCREMENT,\n\torder_type INT,\n\tcustomer_id INT,\n\tamount DECIMAL(10, 2),\n\tPRIMARY KEY (id),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(customer_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(customer_id) TBPARTITIONS 1",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/db1_${dbIndex}/orders_${index}",
"tableNum":"1",
"tableMethod":"mod_hash(customer_id)",
"storeNum":2,
"dbMethod":"mod_hash(customer_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}最后查看一下切分的结果 :
7.3.5 创建 ER 表
关联表也称为绑定表或者 ER 表。表示数据逻辑上有关联性的两个或多个表 , 例如订单和订单详情表。对于关联表 , 通常希望他们能够有相同的分片规则 , 这样在进行关联查询时 , 能够快速定位到同一个数据分片中。
# 在 Mycat 终端直接运行建表语句进行数据分片
CREATE TABLE orders_detail(
id BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8 dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id) tbpartitions 1 dbpartitions 2;
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);对比一下数据 , 会发现由于我们分片字段不同 , 导致 ER 分片表条目不对应 :
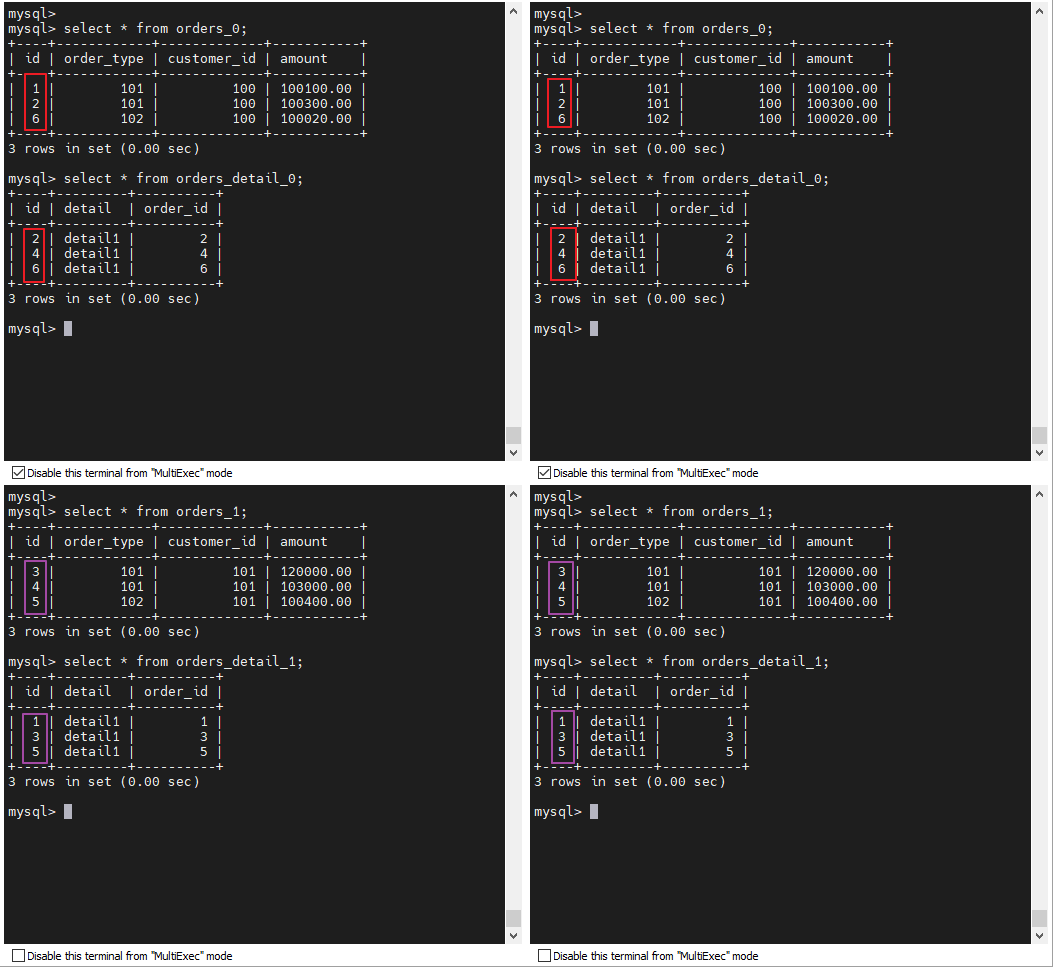
上述两表具有相同的分片算法 , 但是分片字段不相同 , mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推。mycat2 无需指定 ER 表 , 是自动识别的 , 具体看分片算法的接口。
查看配置的表是否具有 ER 关系 , 使用 :
mysql> /*+ mycat:showErGroup{}*/;
+---------+------------+---------------+
| groupId | schemaName | tableName |
+---------+------------+---------------+
| 0 | db1 | orders |
| 0 | db1 | orders_detail |
+---------+------------+---------------+
2 rows in set (0.00 sec)group\_id 表示相同的组 , 该组中的表具有相同的存储分布 , ER 关系暂时不检查分区的目标是否相同 , 仅使用分片算法判断是否满足 ER 关系。
mysql> SELECT * FROM orders o INNER JOIN orders_detail od ON od.order_id=o.id;
+----+------------+-------------+-----------+-----+---------+----------+
| id | order_type | customer_id | amount | id0 | detail | order_id |
+----+------------+-------------+-----------+-----+---------+----------+
| 1 | 101 | 100 | 100100.00 | 1 | detail1 | 1 |
| 2 | 101 | 100 | 100300.00 | 2 | detail1 | 2 |
| 3 | 101 | 101 | 120000.00 | 3 | detail1 | 3 |
| 4 | 101 | 101 | 103000.00 | 4 | detail1 | 4 |
| 5 | 102 | 101 | 100400.00 | 5 | detail1 | 5 |
| 6 | 102 | 100 | 100020.00 | 6 | detail1 | 6 |
+----+------------+-------------+-----------+-----+---------+----------+
6 rows in set (0.08 sec)参考链接
MyCat2测试实战 -- 王者归来的故事_mycat2.0和mycat1.6区别-CSDN博客

