
生成指定位数的随机口令:
cat /dev/urandom | tr -dc '[:alnum:]' | head -c20tr -dc '[:alnum:]_' </dev/urandom | head -c20openssl rand -base64 30 |head -c20
1 文件整理、排序
1.1 cut
用来显示行中的指定部分 , 删除文件中指定字段。显示文件或
STDIN数据的指定列
语法 :
cut [OPTION]...[FILE]...OPTIONS
-d DELIMITER:指定分隔符 , 默认tab-f FILEDS:#:第#字段#,#[,#]: 离散的多个字段 , 例如1,3,6混合使用:1-3,7
#-: 从#开始字段、字节、字节之后的所有字段-#:从开始到#字符、字段、字节
-c: 按字符切割-b: 按字节切割--complement: 选项提取指定字段之外的列 ;--output-delimiter=STRING: 指定输出分隔符
示例:
cut -d: -f1 /etc/passwd
cat /etc/passwd | cut -d: -f7
[root@localhost ~]# cat FILE
abcdefghijklm n
abc defghijklmn
abcdefgh ijklmn
abcd efghijklmn
[root@localhost ~]# cut -c1- FILE
abcdefghijklm n
abc defghijklmn
abcdefgh ijklmn
abcd efghijklmn
[root@localhost ~]# cut -c1-5 FILE
abcde
abc d
abcde
abcd
[root@localhost ~]# cut -b1-5 FILE
abcde
abc d
abcde
abcd
[root@localhost ~]# cut -b1-5 --complement FILE
fghijklm n
efghijklmn
fgh ijklmn
efghijklmn
[root@localhost ~]# cut -c1,5 FILE
ae
ad
ae
a
默认的分隔字符是制表符(
\t: table键)
1.2 wc
wc:收集文本统计数据。 计数单词总数 , 行总数 , 字节总数和字符总数
wc sotry.txt
39 237 1901 story.txt
行数 字数 字节数常用选项:
-l: 只计数行数-w: 只计数单词总数-c: 只计数字节总数-m: 只计数字符总数-L显示文件中最长行的长度
1.3 sort
文本排序
sort把整理过的文本显示在STDOUT,不改变原始文件
语法:
sort [OPTIONS] filesOPTIONS:
-r: 执行反方向(由上至下)整理-n: 执行按数字大小整理-f: 选项忽略(FOLD)字符串中的字符大小写-u: 选项(独特 ,unique)删除输出中的重复行-t c: 选项使用c作为字段界定符-k X: 选项按照使用c字符分隔X列来整理能够使用。选项中1.2表示从第一个字段第二个字母开始排序 ,1.2,1.2, 排序顺序是从第一字段的第二个字母开始到 , 到第一个字段的第二个字母结束。如果-k #:#字段相同时 , 会继续在后一个字段中开始比较。-c: 检查文件是否已经按照顺序排序 ;
[root@localhost ~]# sort -c /etc/passwd
sort: /etc/passwd:2: disorder: bin:x:1:1:bin:/bin:/sbin/nologin
#只针对公司英文名称的第二个字母进行排序 , 如果相同的按照员工工资进行降序排序
$ sort -t ' ' -k 1.2,1.2 -nrk 3,3 facebook.txt
baidu 100 5000
google 110 5000
sohu 100 4500
guge 50 3000
# 从公司英文名称的第二个字母开始进行排序:
$ sort -t ' ' -k 1.2 facebook.txt
baidu 100 5000
sohu 100 4500
google 110 5000
guge 50 3000
1.4 uniq
uniq命令用于检查及删除文本文件中重复出现的行列
语法:
uniq [OPTION]...[FILE]...OPTIONS
-c:显示每行重复出现的次数-d:仅显示重复过的行-u:仅显示不曾重复的行
连续且完全相同方为重复
常和sort 命令一起配合使用: sort userlist.txt | uniq -c
1.5 cloume
语法 :
column [options] [file ...]OPTION
-c, --columns <width>: width of output in number of characters-t, --table: 输出形成一个表格-s, --separator <string>: 识别输入文件的分割符-o, --output-separator <string>:指定输出格式的分割符.默认为两个空格符-x, --fillrows: 更改排列顺序 ( 左→右 ) 。默认的顺序为 ( 上→下 )
使用时所有选项一般与
-t一起连用
[root@centos7 ~]# cat /etc/fstab | column -t
#
# /etc/fstab
# Created by anaconda on Mon Aug 16 15:52:06 2021
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=5495ca80-d3ac-4918-8ca3-8e30f6fb2ced /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
[root@centos7 ~]#
1.6 tr
tr是个简单的替换命令 , 从标准输入中替换、缩减和/或删除字符 , 并将结果写到标准输出。
语法 :
tr [OPTION]... SET1 [SET2]OPTIONS
-c/-C/--complement: 取字符集的补集-d/--delete:删除所有属于第一字符集的字符-s/--squeeze-repeats: 把连续重复的字符以单独一个字符表示-t/--truncate-set1:将第一个字符集对应字符转化为第二字符集对应的字符
字符集合范围
\NNN: 八进制的字符NNN\\: 反斜杠\a:Ctrl-G铃声\b:backspace退格符\f: 换页符\n: 换行符\t:制表符\r: 回车\v: 水平制表符CHAR1-CHAR2: 字符范围从CHAR1到CHAR2的指定 , 范围的指定以ASCII码的次序为基础, 只能由小到大 , 不能由大到小。[CHAR*]: 这是SET2专用的设定 , 功能是重复指定的字符到与SET1相同长度为止[CHAR*REPEAT]: 这也是SET2专用的设定 , 功能是重复指定的字符到设定的REPEAT次数为止(REPEAT的数字采8进位制计算 , 以0为开始)[:alnum:]:所有字母字符与数字[:alpha:]: 所有字母字符[:blank:]: 所有水平空格[:cntrl:]: 所有控制字符[:digit:]: 所有数字[:graph:]: 所有可打印的字符(不包括空格符)[:lower:]: 所有小写字母[:print:]: 所有可打印的字符(包括空格符)[:punct:]: 所有标点字符[:space:]: 所有水平与垂直空格符[:upper:]: 所有大写字母[:xdigit:]: 所有16进制位的数字[=CHAR=]: 所有符合指定的字符(等号里的 CHAR , 代表你可自订的字符)
如果同时指定了SET1和SET2 , 则是将SET1的符号按位置一一对应映射为SET2中的符号。换句话说 , 就是对应替换。
tr接收到stdin后首先会把将结果按照某种标记符号进行换行。例如 :
[root@centos7 tmp]# echo 1234 > a
[root@centos7 tmp]# cat a | tr "1234" "abcde"
abcd默认情况下如果SET1长度比SET2长时,默认最后多余的字符直接对应SET2的最后一个字符
[root@centos7 tmp]# cat a | tr "1234" "abc"
abcc
[root@centos7 tmp]# cat a | tr "1" "abc"
a234以下示例用于说明-t选项。当SET1长度比SET2长时,SET1多余的部分字符将不会被替换
[root@centos7 tmp]# cat a | tr -t "1234" "abc"
abc4
[root@centos7 tmp]# cat a | tr -t "1" "abc"
a234-s命令只用于压缩连续重复的字符。如果不指定SET2 , 则仅只压缩 , 不做替换。SET1可以指定多个字符 ,这样会对每个字符都进行压缩。如果指定了SET2 ,则压缩后还一一对应地进行替换。
[root@centos7 tmp]# echo 112333445678 > b
[root@centos7 tmp]# cat b | tr -s "134"
12345678
[root@centos7 tmp]# cat b | tr -s "134" "-"
-2-5678tr -d是删除指定的符号 , 只能接一个SET1。
tr -c SET1 SET2是将标准输入按照SET1求补集 , 并将补集部分的字符全部替换为SET2 , 即将不在标准输入中存在但SET1中不存在的字符替换为SET2的字符。但是SET2如果指定的字符大于1个 , 则只取最后一个字符作为替换字符。使用-c的时候应该把-c SET1作为一个整体 , 不要将其分开。
[root@centos7 tmp]# cat b
112333445678
[root@centos7 tmp]# cat b | tr -c "13" "y"
11y333yyyyyyy[root@centos7 tmp]#
#这里可以看到最后的换行符也变成了y-c常和-d一起使用 , 如tr -d -c SET1。它先执行-c SET1求出SET1的补集 , 再对这个补集执行删除。也就是说 ,最终的结果是完全匹配SET1中的字符。注意 , -d一定是放在-c前面的 , 否则被解析为tr -c SET1 SET2 , 执行的就不是删除补集 , 而是替换补集为-d的最后一个字符d了。
[root@centos7 tmp]# echo "one 1 two 2 three 3"| tr -d -c "[0-9]\n" # 对数字和分行符求补集 , 并删除这些补集符号
123
[root@centos7 tmp]# echo "one 1 two 2 three 3"| tr -d -c "[0-9] \n" # 再加一个空格求补集
1 2 3
[root@centos7 tmp]# echo "one 1 two 2 three 3"| tr -c "[0-9] \n" -d #-d选项放在-c选项的后面是替换行为
ddd 1 ddd 2 ddddd 3
[root@node02 ~]# echo "one 1 two 2 three 3"| tr -c "[0-9] \n" d
ddd 1 ddd 2 ddddd 3
[root@centos7 tmp]# echo "one 1 two 2 three 3"| tr -d -c "[:alpha:] \n" # 保留字母的同时保留空格
one two three
2 文件比较
2.1 diff && patch
一行一行比较文件
2.1.1 diff用法
语法 :
diff [OPTION]... FILESOPTIONS
-b: 忽略空格造成的不同-B: 忽略空行造成的不同-r: 比较子目录中的文件-u: 以合并的方式来显示文件内容的不同。多用于补丁-y: 可以将屏幕分成左右两部分 , 来比较两个文件之间的差异。-a:diff预设只会逐行比较文本文件 ;-c:显示全部内容 , 并标出不同之处 ;-n/--rcs:将比较结果以RCS的格式来显示-N/--new-file: 在比较目录时 , 若文件A仅出现在某个目录中 , 预设会显示 :Only in目录, 文件A若使用-N参数 , 则diff会将文件A与一个空白的文件比较 ;-q/--brief: 仅显示有无差异 , 不显示详细的信息 ;-x<文件名或目录>/--exclude<文件名或目录>: 不比较选项中所指定的文件或目录 ;-X<文件>/--exclude-from<文件>: 您可以将文件或目录类型存成文本文件 , 然后在=<文件>中指定此文本文件 ;-e: 将比较的结果保存成一个ed脚本 , 之后ed程序可以执行该脚本文件 , 从而将file1修改成与file2的内容相同 , 这一般在patch的时候有用
使用示例 : -e
[root@localhost ~]# cat 1
11
888
999
55
55
[root@localhost ~]# cat 1.ls
11
22
33
55
[root@localhost ~]# diff -e 1 1.ls
5a
.
2,4c
22
33
.
[root@localhost ~]# diff -e 1 1.ls > script.txt
[root@localhost ~]# cat script.txt
5a
.
2,4c
22
33
.
[root@localhost ~]# echo "w" >> script.txt
#这样就是生成了一个ed可以执行的脚本文件script.txt , 生成脚本文件之后我们还需要做一个操作 , 在脚本文件末尾添加ed的write指令 , 只需要执行 echo "w" >>script.txt 将w指令附加到脚本文件的最后一行即可。
[root@localhost ~]# ed - 1 < script.txt
[root@localhost ~]# cat 1
11
22
33
55
注意中间的 – 符号表示从标准输入中读取 , 而 < script.txt 则重定向script.txt的内容到标准输入。这样执行之后1的内容将与1.ls完全相同。
普通模式 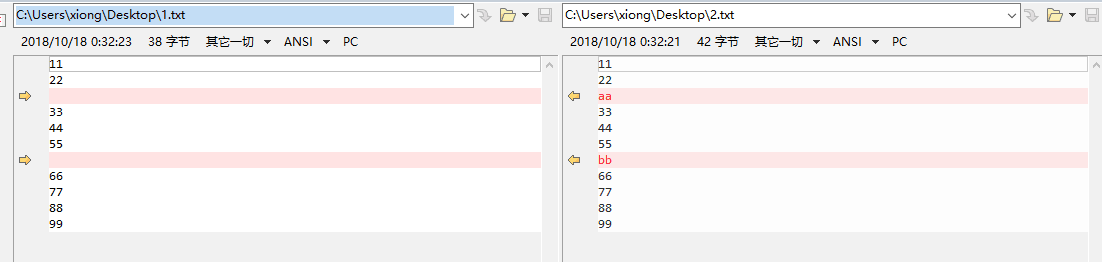
[root@localhost ~]# diff 1 2
3c3
<
---
> aa
7c7
<
---
> bb
这个命令中显示 , <表示文件1,>表示文件2,显示左右文件内容之间的区别。
[root@localhost ~]# diff -c 1 2
*** 1 2018-10-17 12:47:24.971679928 -0400
--- 2 2018-10-17 12:47:45.252865409 -0400
***************
*** 1,4 ****
apples
! oranges
kiwis
carrots
--- 1,5 ----
apples
!
kiwis
carrots
+ grapefruits
上面为文件1 , 下面为文件2.表示区别的地方 , + 表示该文件中多的内容
[root@localhost ~]# diff -u 1 2
--- 1 2018-10-17 12:47:24.971679928 -0400
+++ 2 2018-10-17 12:47:45.252865409 -0400
@@ -1,4 +1,5 @@
apples
-oranges
+
kiwis
carrots
+grapefruits
左边用-号,右边为+号。 -oranges,+ 表示左边与区别的内容,+grapefruits , 表示右边文件多出的内容 , 使用方式与-c方式类似。
[root@localhost ~]# cat test1/
2 3 6
[root@localhost ~]# cat test2/
2 3 5
[root@localhost ~]# diff test1 test2
diff test1/2 test2/2
2c2
< oranges
---
>
4a5
> grapefruits
Only in test2: 5
Only in test1: 6
#第二行改变为oranges就会与右边相同。
#第四行之后加入grapefruits就会与右边第五行相同。
[root@localhost ~]# diff -N test1 test2
diff -N test1/2 test2/2
2c2
< oranges
---
>
4a5
> grapefruits2.1.2 diff补丁用法
diff 命令的输出被保存在一种叫做“补丁”的文件中
使用 -u 选项来输出“统一的(unified)”diff格式文件 , 最适用于补丁文件
diff -urN old/ new/ > mysoft.patch
参数 -u 表示使用 unified 格式 , -r 表示比较目录 , -N表示将不存在的文件当作空文件处理 , 这样新添加的文件也会出现在patch文件中。patch 复制在其他文件中进行的改变(要谨慎使用) 适用-b选项来自动备份改变了的文件
$diff -u foo.conf foo2.conf > foo.patch
$patch -b foo.conf foo.patch在第一个命令中加上
-u选项主要是为了形成一个foo.conf与foo2.conf存在区别的文件 , 将这个内容导入foo.patch, 通过第二个命令是直接通过补丁文件直接将原来的文件备份一份之后 , 生成新内容将原来的内容覆盖掉。生成新的foo.conf就是第一条命令中的foo2.conf
diff命令参考链接:https://www.cnblogs.com/wangqiguo/p/5793448.html#_label2
2.1.3 ed编辑器
是单行纯文本编辑器 , 它有命令模式 (
command mode) 和输入模式 (input mode) 两种工作模式。ed命令支持多个内置命令。
a:切换到输入模式 , 在文件的最后一行之后输入新的内容 ;
c:切换到输入模式 , 用输入的内容替换掉最后一行的内容 ;
i:切换到输入模式 , 在当前行之前加入一个新的空行来输入内容 ;
. : 由输入模式切换至命令模式
d:用于删除最后一行文本内容 ;
n:用于显示最后一行的行号和内容 ;
w:<文件名>:一给定的文件名保存当前正在编辑的文件 ;
q:退出ed编辑器。使用说明
[root@localhost ~]# cat 1
11
888
999
55
55
11
wq
[root@localhost ~]# ed 1
23 #输入ed 1之后会直接显示文件中所有的字符数
2 # 输入行号 , 会显示第二行中的内容
888
# 输入回车之后会默认显示下一行内容
2,3c # 修改2,3行内容
88
99
5 # 当输入完2,3行之后 , 会直接添加在3行之后
. # 退回到命令行模式
wq
23 # 退出时 , 会自动显示文件中所有的字符数
[root@localhost ~]# cat 1
11
88
99
5
55
55
11
wq
[root@localhost ~]# ed 1
23
2i #在文件中第二行添加内容 , 原来的第二行变成第三行
2
.
wq
25
[root@localhost ~]# cat 1
11
2
88
99
5
55
55
11
wq
[root@localhost ~]# ed 1
25
d # 在命令行模式中删除最后一行
w
22
q
[root@localhost ~]# cat 1
11
2
88
99
5
55
55
11
2.2 patch
patch指令让用户利用设置修补文件的方式 , 修改 , 更新原始文件。倘若一次仅修改一个文件 , 可直接在指令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件 , 这也是Linux系统核心的升级方法之一。
语法:
patch [options] [originalfile [patchfile]]patch -pnum <patchfile
OPTIONS
-R: 假设修补数据是由新旧文件交换位置而产生。取消打过的补丁。-E: 若修补过后输出的文件其内容是一片空白 , 则移除该文件。选项说明如果发现了空文件 , 那么就删除它-b: 在打补丁过程中 , 生成一个.orig的备份文件-pnum:num表示忽略目录的层级数目 ,
/1/2/3/4:假设在/下生成的补丁文件 , 打补丁时 , 用户如果在/下 , 则为-p0 ,如果在/1目录下则忽略一级目录,此时运行命令时为-p1
使用示例:
[root@localhost ~]# diff -aurN test1 test2
[root@localhost ~]# patch -p0 < fix.patch #运行这个命令会直接将目录test1中的文件设置成与test2中文件一样,如果再次运行,目录test1则会恢复成原样。
[root@localhost ~]# patch -RE -p0 < fix.patch # 或者直接运行这个命令可以将已经打补丁的目录或文件恢复成原样。
$patch -b foo.conf foo.patch #如果是文件可以直接运行这个命令保证补丁打成功 , 而且会自动生成备份文件。
参考链接
Linux tr命令详解 - 小a玖拾柒 - 博客园 (cnblogs.com)
linux命令总结之tr命令 - 琴酒网络 - 博客园 (cnblogs.com)
SHELL脚本--tr命令用法和特性全解 - 骏马金龙 - 博客园 (cnblogs.com)

